6.31 Random Walk and Efficient Markets Are Not the Same Thing
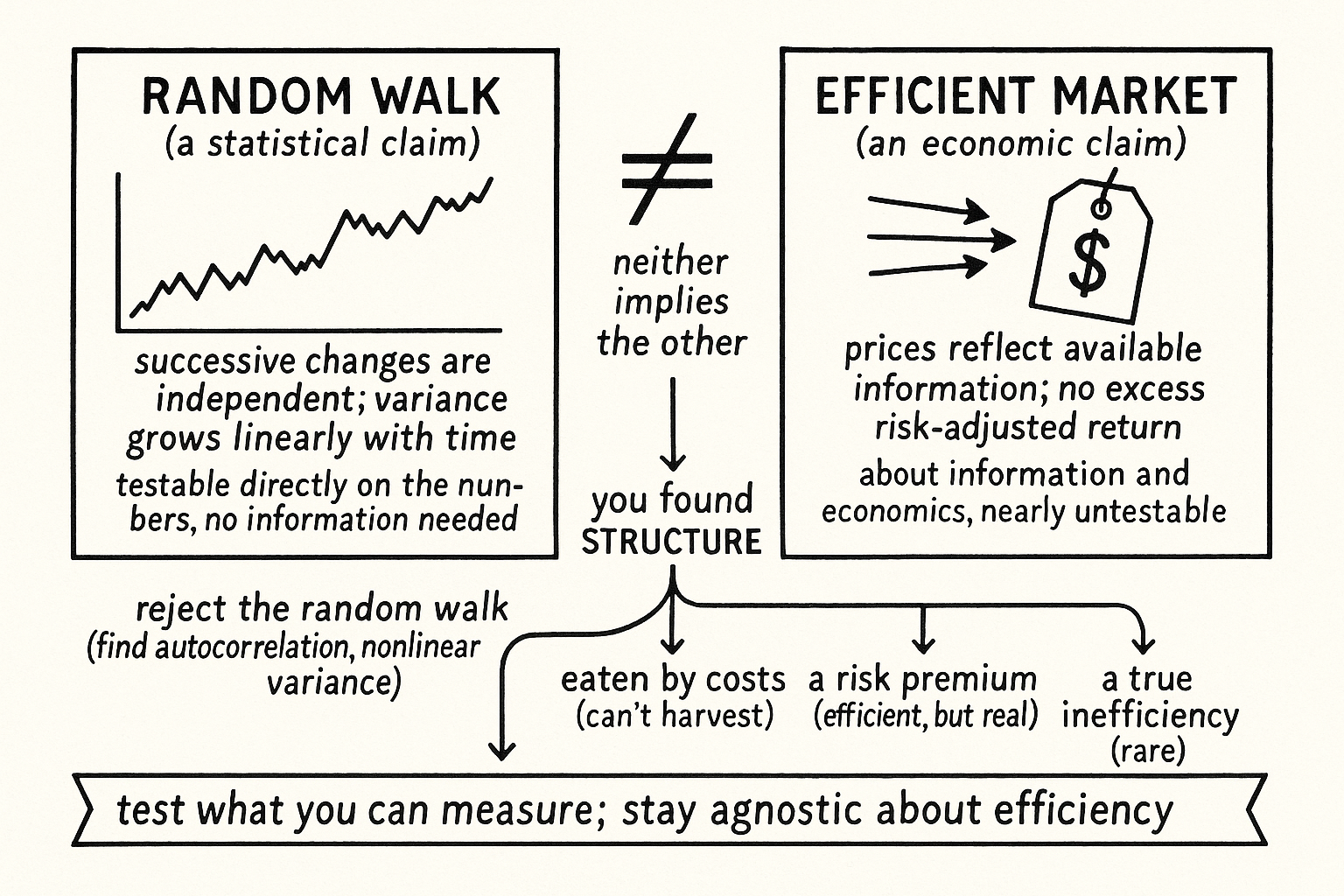
Random walk and efficiency are different claims, one statistical, one economic, neither implying the other. Reject the random walk without calling the market inefficient, and that's where edges hide.

Traders use "random walk" and "efficient market" as synonyms, and they are not. The two ideas get welded together in textbooks into a single discouraging slogan, the market is efficient so prices are a random walk so you cannot win, and the slogan is wrong on the logic. A random walk is a statistical statement about the sequence of price changes. Market efficiency is an economic statement about information. Neither implies the other, and untangling them is the difference between believing no edge can exist and knowing where edges actually hide. This opens the final run in this pillar, the one that treats price as a physical process to be measured rather than a chart to be read.
Two different claims about prices
The random walk hypothesis says that successive price changes are statistically independent, that tomorrow's return has no predictable relationship to today's, so the increments are uncorrelated and the variance of returns grows linearly with time. It is a claim you can test directly on the price series, with no reference to information, value, or rationality. You take the returns and you measure whether they are independent. That is all the random walk is: a property of the numbers.
The efficient market hypothesis says something else entirely, that prices fully reflect available information, so you cannot earn excess risk-adjusted returns using that information because it is already in the price. This is a claim about economics and information, not about the statistical pattern of increments. An efficient market can have predictable price changes, as long as the predictability corresponds to risk premia or costs that prevent anyone from profiting, and an inefficient market can look statistically random if the inefficiencies are complex enough to evade simple tests. The two hypotheses live in different domains, and the point has been made sharply: random walk and efficient markets are not equivalent statements, one does not imply the other and vice versa.
Why the distinction matters for finding edges
The practical payoff is that you can reject the random walk without claiming the market is inefficient, and that rejection is where systematic edges come from. If you test a price series and find that the increments are not independent, that there is autocorrelation, that variance does not grow linearly with time, you have falsified the random walk for that series. You have not necessarily found free money, because the predictability might be a risk premium you are being paid to bear, but you have found a statistical structure, and statistical structure is the raw material of every quantitative strategy. The momentum and mean-reversion signals throughout this pillar all live on departures from the random walk.
Conflating the two hypotheses talks you out of looking. A trader who believes random walk and efficiency are the same thing, and believes the market is efficient, concludes that prices must be a random walk and stops testing, when the testable claim, the random walk, is frequently false in ways the economic claim, efficiency, does not forbid. The honest position is to test the statistical claim directly, because it is testable, and to stay agnostic about the economic claim, because it is nearly untestable, you can never observe the full information set or the true risk premia. Test what you can measure, the independence of increments, and let the economics argue with itself.
The structure is real but not necessarily free
The caveat that keeps this honest: finding a departure from the random walk is necessary for an edge and nowhere near sufficient. The autocorrelation you measure might be entirely consumed by trading costs, so the structure exists statistically and cannot be harvested, the exact trap from "Cost-Aware Ranking: The Missing Step in Cross-Sectional Strategies". It might be a risk premium, real predictability that pays you precisely because it exposes you to a risk that occasionally bites hard, in which case the market is efficient and the random walk is still false and you still might want the trade for the premium. Or it might be a genuine inefficiency that real money can extract, which is the rarest and most competed-for case. Rejecting the random walk tells you the structure is there; it does not tell you which of these three it is, and sorting that out is the work. The point is only that the work is worth starting, which the efficiency slogan tells you it is not.
Visualizing the two hypotheses
KEY POINTS
- "Random walk" and "efficient market" are not synonyms. A random walk is a statistical claim about price changes; efficiency is an economic claim about information. Neither implies the other.
- The random walk says successive price changes are independent and variance grows linearly with time. It is testable directly on the price series, with no reference to information.
- The efficient market hypothesis says prices reflect available information so you cannot earn excess risk-adjusted returns. An efficient market can still have predictable changes if they correspond to risk premia or costs.
- You can reject the random walk without claiming the market is inefficient, and that rejection, finding autocorrelation or nonlinear variance growth, is where systematic edges come from.
- Conflating the two talks you out of looking. Believing they are the same and believing in efficiency makes you conclude prices must be random and stop testing the claim that is frequently false.
- A departure from the random walk is necessary but not sufficient for an edge. The structure might be eaten by costs, paid as a risk premium, or a true inefficiency, and sorting which is the work worth starting.
References
- Systematic Trading - Robert Carver (Amazon)
- Trading Systems - Urban Jaekle Emilio Tomasini (Amazon)
- Stock Market Prices Do Not Follow Random Walks: Evidence from a Simple Specification Test
- Tests of the Random Walk Hypothesis Against a Price-Trend Hypothesis
- Some Statistical Models for Durations and Their Applications to High Frequency Data in Finance
- Financial Time Series: Stylized Facts for the Mexican Stock Exchange Index IPC
- Investment Returns Are NOT Random
- The Impact of Volatility Targeting
- Forecasting Stock Market Volatility and Application to Volatility Timing and Volatility Targeting Portfolio Strategies
- Measuring Strategy-Decay Risk: Minimum Regime Performance and Maximum Regime Slump