6.1 Ranking Beats Forecasting for Many Trading Problems
For cross-sectional strategies you don't need to predict returns, only to order them. Ranking throws away the fragile magnitude and keeps the part that survives regime shifts.

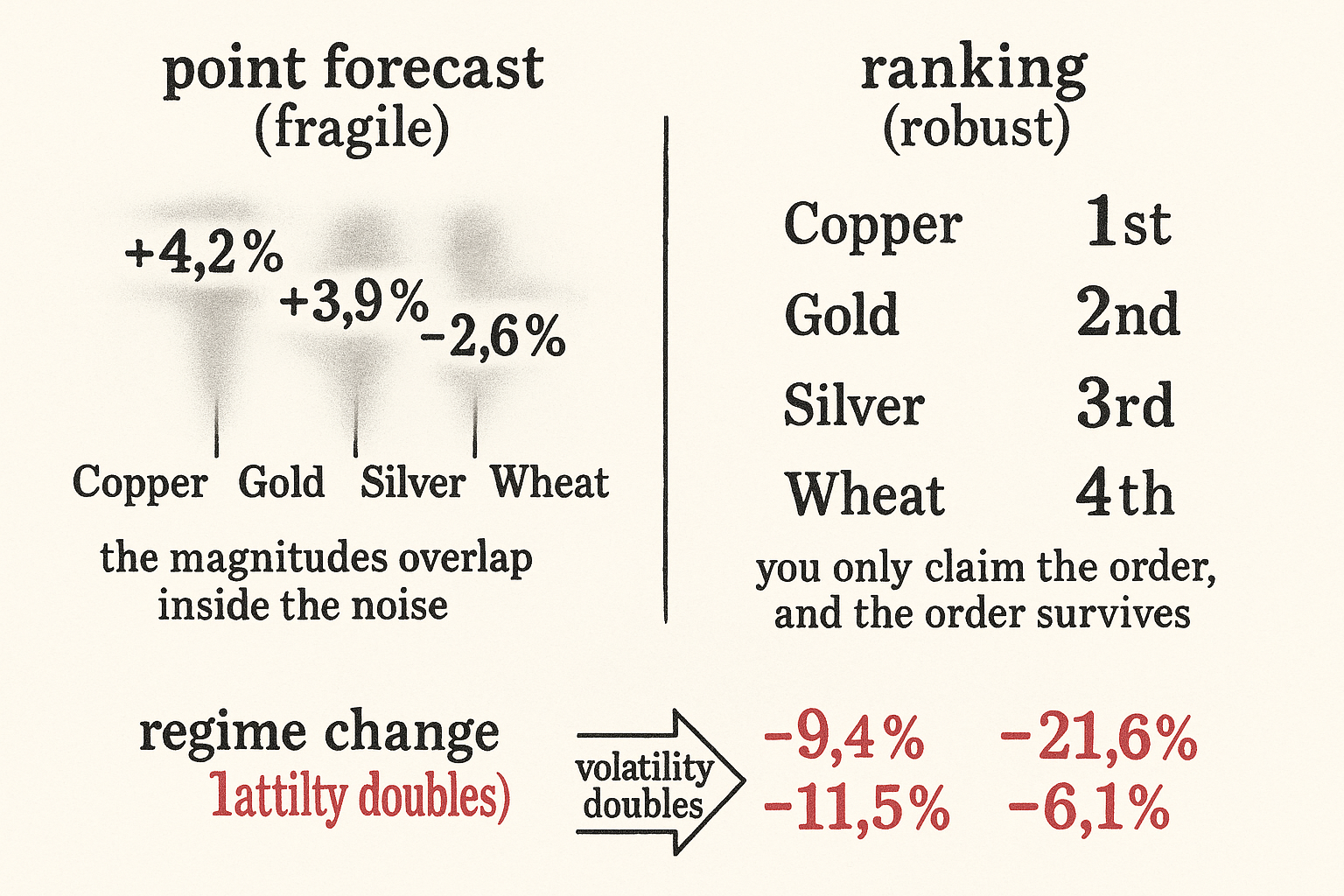
Most traders reach for a forecast when the problem only needs an ordering. They build a model to predict that copper returns 4.2% over the next month, sweat over whether it is 4.2% or 3.1%, and then trade off a number that was never stable to begin with. For a large class of strategies you do not need the number at all. You need to know that copper looks better than gold this month, and gold looks better than silver. That is a ranking problem, and ranking is both easier to get right and harder to break than point forecasting.
The distinction runs through the rest of this pillar, so it is worth nailing down before "Ranked Long/Short Systems Explained" builds the machinery on top of it.
A point forecast asks for more than you can deliver
To forecast an absolute return you have to be right about two things: the direction and the magnitude. The magnitude is where forecasts go to die. Expected returns are tiny relative to the noise around them, so your estimate of "4.2%" carries a standard error wide enough to swallow the whole signal. You are committing to a precise number that the data cannot support, and every downstream sizing decision inherits that false precision.
Ranking throws the magnitude away on purpose. You are not claiming copper returns 4.2%; you are claiming copper sits above gold in this month's ordering. That claim survives even when your absolute return model is badly miscalibrated, because a monotone error that shifts every estimate up or down leaves the ordering intact. The information you actually trade on is the part of the forecast that was robust anyway.
Why the ordering is the stable part
Consider what happens across a regime change. Volatility doubles, the dispersion of returns blows out, and every point forecast you made last month is now the wrong scale. A model trained to output return magnitudes is quoting numbers from a distribution that no longer exists. The cross-sectional ordering, though, tends to persist: the cheap-carry instrument is still cheaper-carry than the expensive one, the strong-momentum instrument still has stronger momentum than the weak one, even as the absolute numbers move.
$$ \rho_s = 1 - \frac{6 \sum_{i=1}^{n} d_i^2}{n(n^2 - 1)} $$
This is the Spearman rank correlation, the natural way to score a ranking model. The d terms are the differences between each instrument's predicted rank and its realized-return rank, n is the number of instruments, and the score runs from -1 to +1. It only cares about order, not distance, so a model that nails the ordering but mangles the magnitudes scores a perfect 1. That is the right scoring rule for a ranking system, and the fact that it ignores magnitude is the whole point: you are grading the part of the forecast you can actually trust.
When ranking is not enough
Ranking is the right tool when you trade a cross-section, a basket where you can be long the top and short the bottom and you only care about relative performance. It is the wrong tool when the absolute level matters. A single-instrument timing system that decides whether to be in or out of the S&P cannot rank one thing against nothing; it needs a real forecast of whether the move is worth the cost. A volatility-targeting overlay needs the magnitude of expected return to size the bet, which is why "Why Volatility-Adjusted Position Sizing Matters" treats sizing as a separate problem from selection. Ranking solves selection cleanly and says nothing about how hard to bet, so you pair it with a sizing layer rather than asking it to do both.
Visualizing rank vs magnitude
KEY POINTS
- A point forecast commits you to direction and magnitude. Magnitude is where forecasts fail, because expected returns are tiny next to the noise around the estimate, so the precise number carries a standard error wide enough to swallow the signal.
- Ranking discards magnitude on purpose. You claim only that one instrument sits above another, and that claim survives a miscalibrated return model, since a monotone error leaves the ordering intact.
- The cross-sectional ordering is the stable part across regime changes. When volatility doubles, point forecasts are the wrong scale, but the relative ordering of carry, momentum, or value tends to persist.
- Score a ranking model with Spearman rank correlation, which grades order and ignores distance. A model that nails the ordering but mangles the magnitudes still scores a perfect 1.
- Ranking is for cross-sectional selection, where you go long the top and short the bottom and only relative performance matters. It says nothing about how hard to bet.
- Pair ranking with a separate volatility-based sizing layer. Use a real forecast only where the absolute level matters, like single-instrument timing.
References
- Systematic Trading - Robert Carver (Amazon)
- Trading Systems - Urban Jaekle Emilio Tomasini (Amazon)
- Volatility Scaling in Multi-Asset Portfolios
- LambdaRankIC: Directly Optimizing Rank IC for Financial Prediction
- Construction of Minimum Spanning Trees from Financial Returns using Rank Correlation
- Econometric Modeling to Measure the Efficiency of Sharpe's Ratio in Investment Portfolios
- Optimal Portfolio Strategy to Control Maximum Drawdown
- Enhancing Currency Portfolio Construction through Kendall's Tau
- The Impact of Volatility Targeting
- Kendall Correlation Coefficients for Portfolio Optimization - arXiv
- A Deep Multi-Factor Framework for Cross-Sectional Stock Return Prediction
- Stock portfolio selection using learning-to-rank algorithms with news sentiment
- Do Better Volatility Forecasts Lead to Better Portfolios? Evidence from Graph Neural Networks and Volatility Targeting
- Forecasting Stock Market Volatility and Application to Volatility Timing Portfolios
- Factor Portfolio and Target Volatility Management
- Pairs trading and outranking: The multi-step-ahead forecasting case
A note on AI. The ideas, research, analysis, and conclusions in this article are my own. I use AI tools to help with editing and wordsmithing, because English is not my first language, and I am not shy about that. AI-generated ideas and AI-assisted writing are not the same thing: the first is empty slop from a generic prompt, the second is a tool for communicating years of real research more clearly. Judge the work by its substance, not by whether software helped polish the prose.