6.46 Signal Averaging: Killing Noise with Redundant Alphas
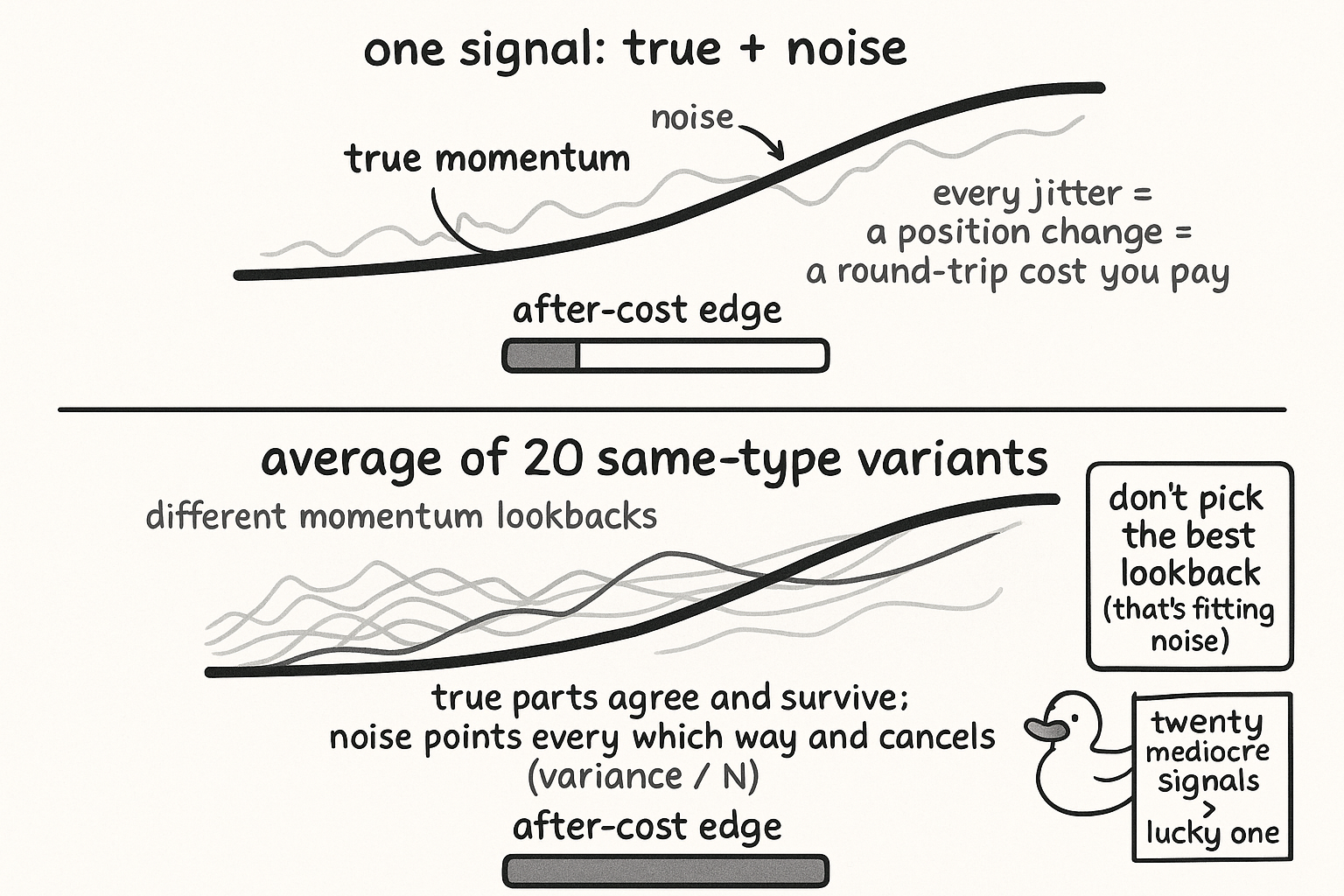
Most of your cost is trading the noise in a signal, not the edge. Build 10 to 20 variants of one alpha and average: true parts survive, noise divides by N. Don't pick the best lookback, keep them all.

Most signals that look good in research die after costs. You build a momentum estimator, the in-sample curve climbs, and then you charge it spread and slippage on every position change and the edge evaporates. The reflex is to smooth the signal or trade it less, and those help, but they treat the symptom. The disease is that your signal is paying transaction costs to trade its own noise, and there is a technique that attacks the noise directly, costs almost nothing to implement, and works for anyone running more than one variant of an alpha.
Your signal is two things stacked
Write any signal as a true component plus a noise component.
$$ \text{signal}_i \;=\; \text{true}_i \;+\; \varepsilon_i $$ $$ \mathbb{E}[\varepsilon_i] = 0, \qquad \operatorname{Var}(\varepsilon_i) = \sigma^2 $$
Read that as: the estimator you actually trade, signal_i, is the thing you want, true_i, which is positively correlated with future returns, plus a noise term epsilon_i that has mean zero and some variance sigma-squared. The noise averages out to nothing over time, so it carries no edge, but it has variance, and variance is what jiggles your target position back and forth. Every jiggle is a round trip you pay for. The old article "Why Forecast Accuracy Is Not Enough in Market Making" makes the cost-side version of the point: a forecast can be right on average and still bleed you if acting on it churns the book.
So most of your transaction-cost bill is not the cost of expressing the true signal. It is the cost of trading the variance of epsilon. Strip the noise and the same true signal trades far less and keeps far more of its gross edge.
Average many copies and the noise shrinks
You cannot see true_i and epsilon_i separately, so you cannot subtract the noise directly. You can drown it. Build many estimators of the same type, ten or twenty momentum signals instead of one, and combine them. The bet you are making is structural: the true components of same-type signals are highly correlated with each other, because they are all reading the same underlying momentum, while their noise components are close to independent, because each variant's noise comes from its own particular lookback and sampling quirks.
Average them and the two components behave completely differently under the sum.
$$ \bar{s} \;=\; \frac{1}{N}\sum_{i=1}^{N}\text{signal}_i \;=\; \underbrace{\frac{1}{N}\sum_i \text{true}_i}_{\text{stays strong}} \;+\; \underbrace{\frac{1}{N}\sum_i \varepsilon_i}_{\text{collapses}} $$ $$ \operatorname{Var}\!\Big(\tfrac{1}{N}\sum_i \varepsilon_i\Big) \;=\; \frac{\sigma^2}{N}\quad\text{when the }\varepsilon_i\text{ are independent} $$
Read the top line as: the average of the signals splits into the average of the true parts and the average of the noise parts. Because the true parts are correlated, averaging them barely dilutes the signal, the mean of a pile of similar things is about as strong as each one. The bottom line is the payoff: the variance of the averaged noise falls by a factor of N when the noise terms are independent, so twenty signals cut the noise standard deviation by about a factor of four and a half. The true signal survives the average, the noise gets divided away, and the signal-to-noise ratio of the combination beats any single member by a wide margin. Fewer noise-driven jiggles means fewer round trips, which is where the after-cost edge comes from.
Where the variants come from
The usual objection is that coming up with twenty signals is hard. It is the opposite of hard once you stop trying to find the one best version.
The standard workflow tunes a momentum lookback, tests 20, 30, 40, 60, 90 days, and ships whichever posted the best in-sample Sharpe. That is selection on noise: you picked the parameter whose particular noise draw happened to flatter the backtest, which is overfitting wearing a respectable hat. Flip it. Instead of choosing the winner, keep all of them and average. Each lookback is a legitimate variant of the same momentum idea, their true components track each other, their noise does not, and the average is both more robust and cheaper to trade than the cherry-picked single. You were already computing the whole sweep to pick a winner, so the averaged version costs you nothing extra to build.
If the signal has a random component, as a machine-learning model does through its seed and its sampling, you get variants for free by changing the seed. Random-seed averaging trains the same model under several seeds and averages the predictions, and the logic is identical: the learned structure is shared across seeds, the seed-specific noise is not, so the average has a cleaner forecast. It is the cheapest variance reduction in the book, and it is the same averaging that the old article "Why Volatility-Adjusted Position Sizing Matters" leans on at the portfolio layer, only applied one level down at the signal layer.
The honest part: the noise is never fully independent
The factor-of-N gain assumes independent noise, and same-type signals never deliver that cleanly. Two momentum estimators with lookbacks of 50 and 55 days are nearly the same signal, so their noise is correlated too, and correlated noise does not divide away at the full rate. The realized gain sits between no improvement, when the variants are identical, and the full factor-of-N, when the noise is independent, and where you land depends on how genuinely different the variants are. This is the same math as portfolio diversification: the old article "The Death of the Single-System Trader" shows that correlated systems give almost no diversification benefit, and correlated signal variants give almost no noise reduction, for the identical reason. So spread the variants out. Use lookbacks that actually differ, mix the construction where you can, and do not fool yourself that ten copies of nearly the same signal bought you ten-fold noise reduction.
This is distinct from stacking different alpha types. The old article "Positional Market Making and the Thousands-of-Alphas Ensemble" combines many genuinely different skews into one book, which is diversification across ideas. Signal averaging is narrower and more specific: it is combining many variants of one idea to clean the noise out of that one idea before it ever reaches the portfolio. You do both, at different layers, and the averaging here is the unglamorous first pass that makes each idea worth putting in the ensemble.
Why averaging beats picking the best
The whole move is a refusal to optimize. Parameter tuning to find the best single signal maximizes in-sample performance, which is the exact quantity that fails to survive out of sample, because the maximum is sitting on top of a favorable noise draw. Averaging across the parameter set throws away the in-sample peak on purpose and keeps the robust center, which is the part that survives. The old article "Parameter Stability Beats Best Parameter" is the general statement and this is the concrete tool: you do not search the parameter space for a winner, you integrate over it and trade the average. The cost is a sliver of in-sample sharpness. The return is a signal that trades less, survives the regime change that moves the best lookback, and keeps its edge after costs.
Visualizing the noise wash
KEY POINTS
- Any signal is a true component plus a zero-mean noise component. The true part carries the edge; the noise part carries only variance, and trading that variance is where most of your transaction-cost bill comes from.
- You cannot subtract the noise directly, so drown it. Build ten to twenty variants of the same alpha type and average them.
- The true components are correlated and survive the average; the noise components are close to independent and their variance falls by a factor of N. The combined signal-to-noise ratio beats any single member, so it trades less and keeps more edge after costs.
- Get the variants for free: instead of tuning one lookback and shipping the best, keep the whole sweep and average it. For ML, average across random seeds.
- The noise is never fully independent. Near-identical variants have correlated noise and give little reduction, the same way correlated systems give little diversification. Spread the variants out and do not overclaim the gain.
- This is signal-layer cleaning, narrower than combining different alpha types into an ensemble. Do both, at different layers.
- Averaging beats picking the best because the in-sample winner is sitting on a lucky noise draw. Integrate over the parameter set instead of searching it for a peak.
References
- Statistically Sound Indicators for Financial Market Prediction - Timothy Masters (Amazon)
- Systematic Trading - Robert Carver (Amazon)
- The Elements of Statistical Learning
- Combination Forecasts of Output Growth (Stock & Watson)
- A Simple, Positive Semi-Definite, Heteroskedasticity and Autocorrelation Consistent Covariance Matrix