2.78 From One Tree to Forests to Boosting
One tree is fragile: a small data change flips its top split. Bagging averages many trees to cut variance; boosting fits each new tree to the residual to cut bias. XGBoost and LightGBM are boosting.
The old article "How a Decision Tree Engineers a New Alpha" built a single tree that mines conditional signals out of cross-sectional features. It works, and it has one fault that sinks it on its own: it is fragile. Change the training sample a little, drop a few thousand rows or shift the window a month, and the top split can flip from a vol-regime cut to a momentum cut, and once the top split moves, every split beneath it is chosen on different data, so the whole tree rebuilds into a different model. A forecast that swings that much on a small data change is fitting the sample, not the market. The old article "Why Volatility Is More Non-Stationary Than Trend" frames why this bites so hard: the signal-to-noise ratio is brutal, and a high-variance model trained on it locks onto the noise.
The fix is the same one that stabilizes a noisy linear model. Train many models on resampled data and average them.
Bagging, borrowed from the linear case
Bagging started as a trick for linear models, and it is worth seeing there first because the logic carries over unchanged. Take the noisy three-feature model from the old article "Feature Engineering Before Machine Learning" and suppose you want a stable live prediction instead of the best in-sample fit. You could split the history into pieces and fit a model on each, but each piece is too small to fit well. So you manufacture more samples instead.
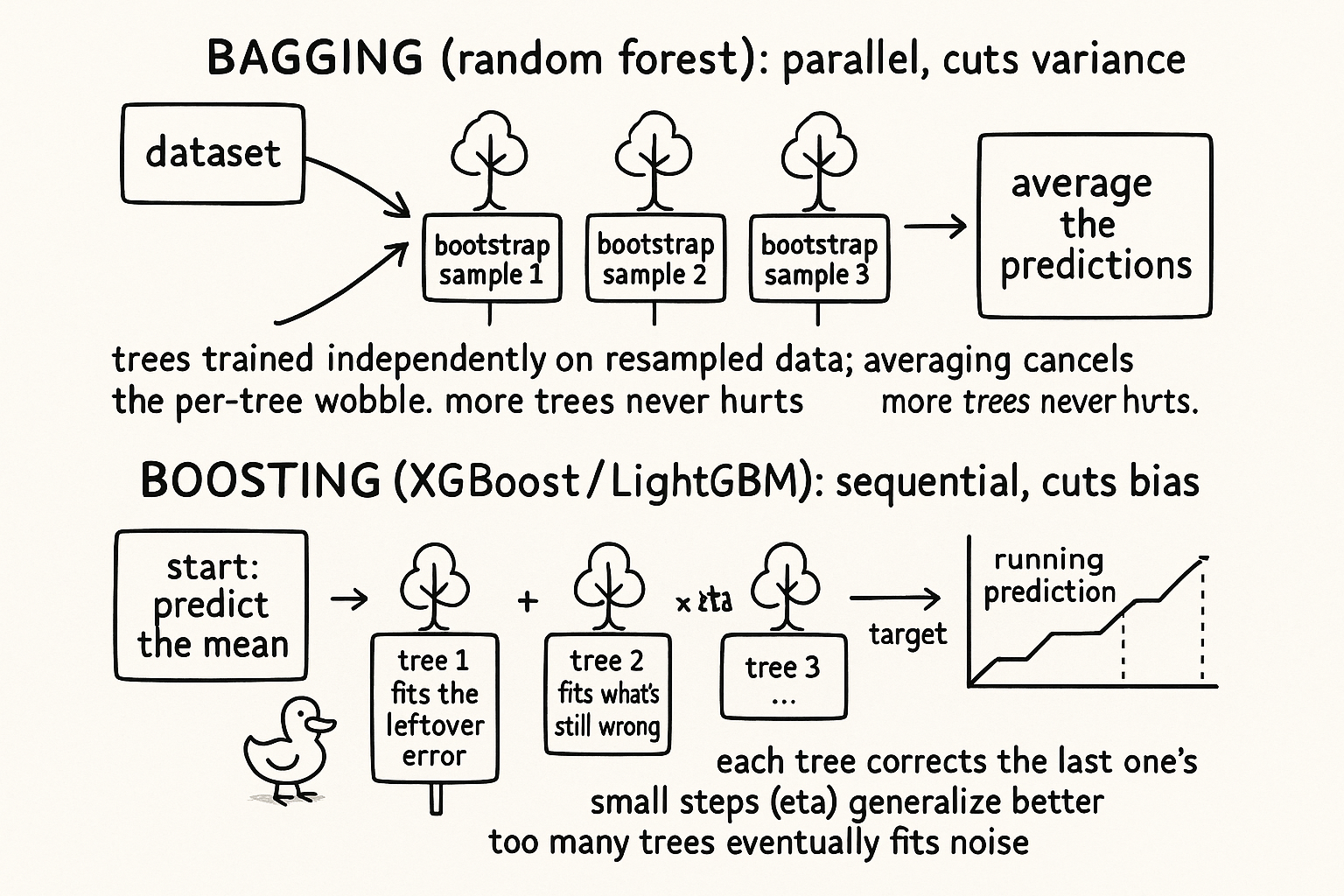
Draw rows from your history at random, with replacement, until you have a new dataset the size of the original. Some rows appear twice, some not at all. This bootstrap sample stands in for "going back out and collecting fresh data," which is what you would do if you could. Fit a model on it. Do it again on a fresh draw, and again, and you get a stack of fitted models.
$$ \hat{f}_1, \; \hat{f}_2, \; \dots, \; \hat{f}_B \quad\Longrightarrow\quad \hat{f}_{\text{bag}}(x) = \frac{1}{B}\sum_{b=1}^{B} \hat{f}_b(x) $$
Each model carries the same average error, the same bias, so averaging them does not fix bias. What averaging fixes is variance. The models disagree because each saw a different resample, and averaging their disagreement cancels a chunk of it, the way the old article on factors and regularization leans on shrinkage to stabilize estimates. You trade a sharper in-sample fit for a forecast that barely moves when the data wobbles.
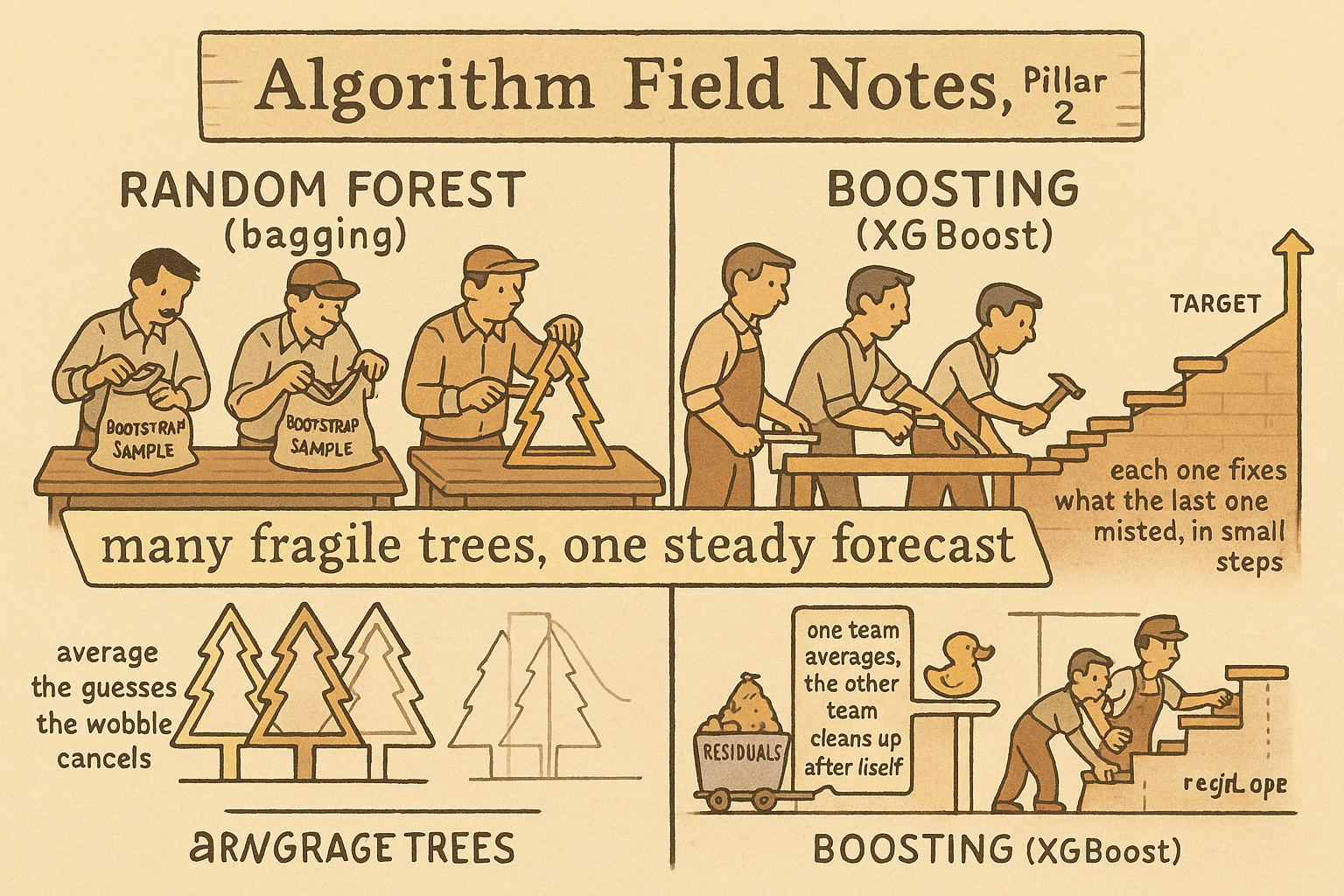
Bagging trees gives a random forest
Run the same procedure on trees and you get a random forest. Each tree trains on its own bootstrap sample, so each tree's fragile top split is chosen from a different draw, and where one tree splits on the vol regime another splits on momentum. Average their predictions and the per-tree fragility washes out, because the thing that made one tree swing, its sensitivity to the exact sample, is exactly what averaging across many samples removes.
data
|-- bootstrap #1 --> tree T_1 -.
|-- bootstrap #2 --> tree T_2 |--> average --> predicted return
|-- bootstrap #3 --> tree T_3 -'
'-- ... --> tree T_B
Forests add one more shuffle: at each split, a tree is allowed to consider only a random subset of the features. That stops every tree from latching onto the single strongest feature and making the trees near-copies of each other. The old article "The Death of the Single-System Trader" makes the portfolio version of this point, that correlated components give you almost no diversification, and it applies here unchanged. Trees that all split on momentum first are correlated and average to nothing better than one tree. Forcing feature subsets decorrelates them, and decorrelated trees average to a steadier forecast.
Boosting fits the next tree to the leftover error
Step back and bagging looks wasteful. Each tree starts from scratch and takes its own swing at the full target, then you throw away their individual structure by averaging. Every tree redoes work the others already did. What if each new tree only worked on the part the current model still gets wrong?
Start with the simplest possible forecast, the overall mean of the target.
$$ \text{pred}_0 = \overline{y} $$
Compute what that leaves on the table, the residuals, which are the actual returns minus the current prediction. Fit a tree to those residuals, not to the original target. That tree learns the structure the current model missed. Add a shrunken piece of it to the running prediction, and repeat.
$$ \text{pred}_n = \text{pred}_{n-1} + \eta \cdot T_n\big(\,y - \text{pred}_{n-1}\,\big) $$
Each tree corrects the last one's mistakes, and the running sum creeps toward a good forecast one small step at a time. This is boosting, and the popular implementations are LightGBM and XGBoost. The learning rate eta is the step size, and it does real work: a small eta takes tiny steps and needs many trees but generalizes better, which is the same plateau-over-peak discipline the old article "Parameter Stability Beats Best Parameter" argues for everywhere. Too large a step and the model chases the residual noise, which at this signal-to-noise is most of the residual.
Bagging and boosting are not the same medicine
The two reduce different errors, and confusing them costs you. Bagging trains its trees independently and in parallel, all on the same target, and averages to cut variance. It rarely overfits as you add trees, because more trees just average more. Boosting trains its trees in sequence, each on the previous residual, and sums them to cut bias by grinding down the error the model has not yet explained. It will overfit as you add trees, because eventually it starts fitting the noise in the residual, so the number of rounds is a parameter you have to control with the same out-of-sample care you give any threshold.
Where interactions dominate, boosting usually wins on accuracy, which is why the next article in this arc, "Ridge Above 1h, XGBoost Below 5min," ends up recommending it at the shorter, interaction-dominated horizons. It wins because the conditional structure of cross-sectional returns is deep there, and stage-by-stage residual fitting digs into that structure further than averaging independent trees does. It costs more tuning and more discipline to keep from overfitting, and it still breaks the long-short symmetry that the old article "Linear Models' Hidden Symmetry Advantage" says you have to engineer back in, because every tree in the ensemble inherits that flaw from the single tree underneath it.
Visualizing the two ensembles
KEY POINTS
- A single decision tree is fragile. A small change in the training sample can flip the top split and rebuild the whole tree, so the forecast swings on noise. At this signal-to-noise this is fatal.
- Bagging stabilizes it. Train many models on bootstrap resamples, drawn with replacement, and average them. Averaging leaves bias alone and cuts variance, trading in-sample sharpness for a forecast that barely moves when the data wobbles.
- Bagging trees gives a random forest. Each tree trains on its own resample, and at each split a tree sees only a random subset of features, which decorrelates the trees so their average actually helps. Correlated trees average to nothing better than one.
- Boosting takes a different route. Start at the mean, fit each new tree to the current residual, and add a shrunken piece. The running sum corrects its own mistakes step by step. The implementations are LightGBM and XGBoost.
- The learning rate eta is the step size. Small steps need more trees and generalize better; large steps chase residual noise. The number of boosting rounds overfits if uncontrolled, unlike bagging.
- Bagging cuts variance in parallel, boosting cuts bias in sequence. Boosting usually wins on accuracy where interactions dominate because the conditional structure of cross-sectional returns is deep, at the cost of more tuning. Every tree in either ensemble still breaks long-short symmetry.