2.77 Linear Models' Hidden Symmetry Advantage
Relabel every long as a short and a return model should flip its sign. Linear models get this free through their weights; a tree relearns each split's mirror, so engineer the symmetry back.

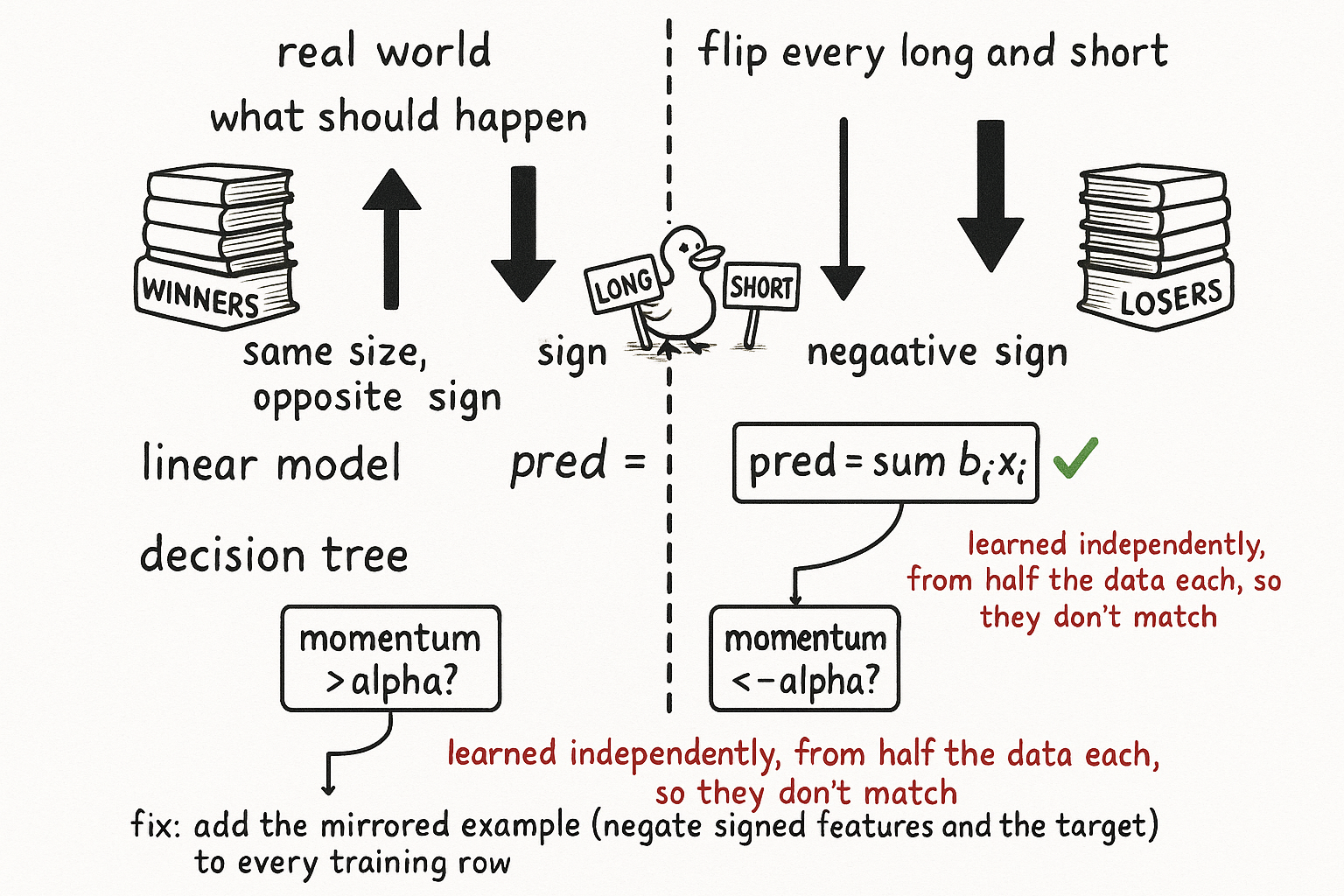
Take every position in a cross-sectional book and flip it. Every long becomes a short, every short becomes a long. The winners you were buying turn into names you sell, a positive momentum reading turns negative, the whole signed feature set reverses. You have built the mirror world, the same strategy reflected across the line between long and short.
Ask what a correct return model should do in that mirror world. If the original model predicted a name was about to outperform, the mirrored model should predict it underperforms by the same amount. The magnitude stays, the sign flips.
$$ \text{pred\_return} \;\longrightarrow\; -\,\text{pred\_return} $$
This is not a nice-to-have. It is a law of the trading world. Going long and going short are symmetric operations on a return, so a model that prices the next move must respect the symmetry, or it is making different claims about winners and losers for no reason the market gives it. The old article "The Limits of Linear Models" spent its length attacking linear models for being unable to capture interactions. This article pays the debt back. The same additivity that makes them blind to interactions hands them this symmetry for free, and the model people are running to instead, the tree, does not get it.
Why the linear model gets it free
Write the linear prediction as the weighted sum it is. Every feature is centered and linearly correlated with the return, so the prediction is the dot product of weights and features.
$$ \text{pred} = \sum_i b_i \, x_i $$
Now flip the world. Mirroring sends every feature to its negative, because momentum, carry, value, and the rest are all signed quantities that reverse when you relabel every long as a short. Feed the negated features through the same fitted weights.
$$ \sum_i b_i \,(-x_i) = -\sum_i b_i \, x_i = -\,\text{pred} $$
The prediction flips sign on its own, exactly as the trading world demands, and you did nothing. You did not retrain, you did not add a constraint, you did not check it. The structure of the model guarantees it. A model with one set of weights describes the long-case and the short-case with the same parameters, so it cannot get one right and the other wrong. It treats them as the single symmetric thing they are.
Why the tree does not
A tree makes its decisions by splitting on feature values. It learns a rule like "is momentum above alpha?" and assigns a prediction to each side.
$$ x_i > \alpha \;? $$
In the mirror world, the feature that was x_i is now its negative, and the split that should fire is the reflection of the original.
$$ x_i < -\alpha \;? $$
A linear model already knew this, because the negative sign carried through the weight. A tree knows nothing of the sort. The split at alpha and the split at minus alpha are two separate questions to a tree, learned from two separate subsets of the data, fit independently with their own samples and their own noise. The tree has to discover both halves of the symmetry on its own, and it has half the data to learn each half with.
That doubles the surface for error. Every place the linear model had one parameter doing symmetric duty, the tree has two estimates that should be mirror images and usually are not, because each was fit on a different slice of a low signal-to-noise sample. The tree can decide momentum above alpha predicts a strong outperformance while momentum below minus alpha predicts a weak underperformance, an asymmetry the market does not contain and the model invented out of sampling noise. In a domain where the old article "Feature Engineering Before Machine Learning" pegs the real signal at a thin slice of total return variance, inventing structure that is not there is exactly the failure you cannot afford.
You have to engineer the symmetry back in
The tree's flexibility is the reason you reach for it. The previous article in this arc made that case: cross-sectional returns are conditional, and a tree conditions natively where a linear model is stuck adding. You do not give that up. You pay for it by re-engineering the symmetry the linear model gave you free.
The clean way is data augmentation. For every training example, add its mirror: negate the signed features and negate the target. The tree now sees both halves of every situation, the long-case and its reflected short-case, in equal measure, so it has no excuse to fit them asymmetrically. You have doubled the effective sample for learning each symmetric rule and removed the source of the invented asymmetry. The cost is real, more data to carry and a constraint to enforce on every feature you add, since you have to know which features are signed and flip them correctly. Get the sign bookkeeping wrong on one feature and you have taught the model a lie.
This is the trade the whole arc keeps returning to. The linear model is rigid, and the rigidity buys you a guarantee. The tree is flexible, and the flexibility costs you the guarantee unless you rebuild it by hand. Neither is free. The mistake is reaching for the tree because it is more powerful and forgetting that some of the linear model's power came from what it could not do.
Visualizing the mirror
KEY POINTS
- Flip every long and short in a book and a correct return model should flip the sign of its prediction while keeping the magnitude. Long-short symmetry is a law of the trading world, not an option.
- A linear model satisfies it for free. Because the prediction is a weighted sum of signed features, negating the features negates the prediction through the same weights, with no retraining and no constraint.
- A tree does not. Its split "is momentum above alpha?" and the mirror split "is momentum below minus alpha?" are two questions learned independently from two halves of the data, so they rarely come out as mirror images.
- The asymmetry a tree invents is sampling noise dressed as structure. In a near-zero signal-to-noise domain, inventing structure that the market does not contain is a direct path to overfitting.
- Recover the symmetry by augmenting the data: for every training row, add its mirror with signed features and target negated. The tree then sees both halves equally and cannot fit them asymmetrically.
- The cost is more data and careful sign bookkeeping on every signed feature. The arc's recurring lesson holds: the tree's flexibility is real, and part of the linear model's strength was a guarantee that came from what it could not do.