9.13 What a Market Price Actually Is: Capital-Weighted Consensus and the Brier Skill Score Gate
A prediction-market price is the capital-weighted consensus, not a probability fact. Coherent prices can still be wrong, but before betting your view, pass the Brier Skill Score gate: beat the market on your own logged forecasts or stop.

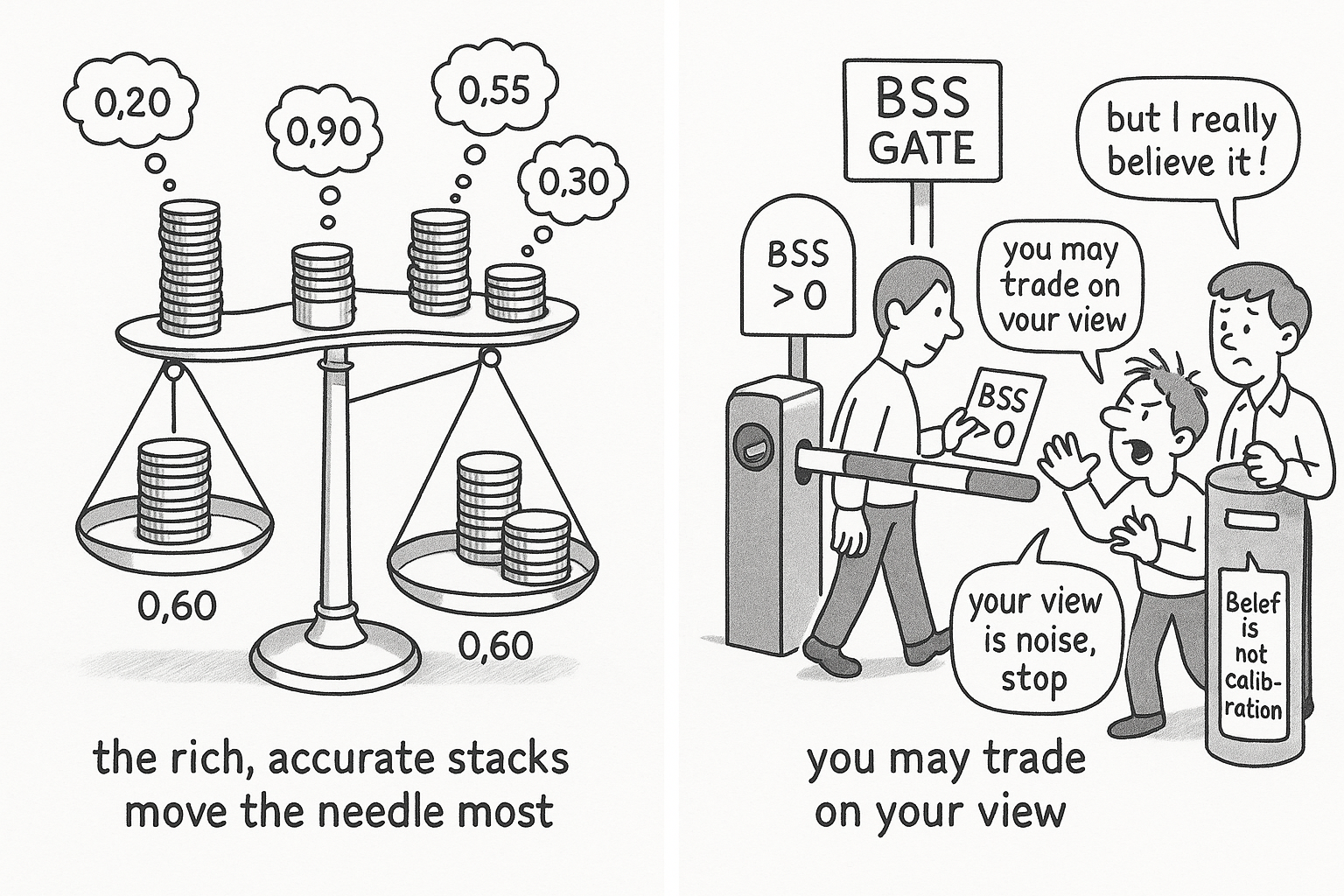
You checked the price point against the marginal polytope from the article on convex geometry and it sits inside. No structural edge. The prices are coherent, which means they contradict no probability law. The next question is whether coherent prices can still be wrong, and the answer is yes, but the trade that exploits it is the dangerous one this pillar ranks fifth of nine. Before you take it, you owe yourself two things: an honest account of what the $0.60 on your screen means, and a hard numerical gate that tells you whether your forecast is allowed to trade at all.
Most participants skip both. They read $0.60 as "the market says 60%," treat that as a fact to disagree with, and bet their disagreement. The price is not a fact. It is the settling point of a capital-weighted argument, and beating it requires proving you are more accurate, not merely more confident.
A price is not a probability
A $0.60 binary contract does not carry a 60% frequentist probability the way a fair die carries one-sixth. It is the price at which the marginal trader stops caring which side to take.
$$ p \;\approx\; \frac{\sum_i W_i \, P_i(H)}{\sum_i W_i} $$
Read that as: the price is roughly a weighted average of every participant's private belief P-i about the event H, where each belief is weighted by that participant's capital W-i, so a rich trader with a wrong view drags the price more than a poor trader with a right one. Each trader bets in proportion to how far their belief sits from the market, and over time capital drains from the inaccurate toward the accurate. The price is the residue of that flow. Call it Darwinian information filtering: the selection pressure acts on capital, not on opinions, and a wrong opinion attached to a large bankroll survives longer than it should.
This reframing matters because it tells you when to trust the number. The old article "The Difference Between Explanation and Prediction in Markets" makes the general case that a confident narrative is not a forecast. Here the price is a genuine forecast, aggregated across money, and the empirical record is good: across 964 polls over five US presidential cycles, prediction-market prices beat the polls about 74% of the time, and the gap widened for forecasts made more than 100 days out. Betting against that aggregate is not free.
When the aggregate breaks
The capital-weighted average is only as good as the capital and the time behind it. Five conditions turn a coherent price into an exploitable one.
Capital concentration: one wealthy, wrong trader moves the price where the crowd would not. Thin liquidity: small trades swing the price out of proportion, so the "consensus" is a handful of orders. Short horizons: selection pressure has not had time to move capital away from the inaccurate, so early prices are noisier. Strategic behavior: manipulation and bluffing distort the signal, especially on high-visibility events. Extreme probabilities: above 0.95 or below 0.05 the payout structure makes betting against a near-certainty expensive even when it is mispriced, which is why edges cluster in the middle of the range and the tails stay sticky.
Notice what every condition has in common. Each is a reason the averaging mechanism failed, not a reason your opinion is right. Your edge, if it exists, lives in the gap the mechanism left open, not in your conviction. The old article "Volatility Regimes and Strategy Survival" makes the parallel point that conditions, not confidence, decide whether a strategy works.
Calibration and sharpness: two different virtues
A forecast has two qualities, and traders confuse them constantly. Calibration: among all the times you said 70%, the event happened about 70% of the time. Sharpness: your forecasts commit, clustering near 0 and 1 rather than hedging at 0.5.
You want both. Calibration without sharpness is useless: a forecaster who says 0.5 to everything is perfectly calibrated and tells you nothing. Sharpness without calibration is dangerous: a forecaster who confidently says 0.9 to things that happen 60% of the time will get sized into ruin by any Kelly rule. The old article "Why Trading Is a Probability Business, Not a Certainty Business" is the foundation here; prediction markets make the payoff binary, so miscalibration shows up faster and costs more.
The Brier score and its decomposition
The Brier score measures forecast quality as the squared error between your probability and the outcome, and it splits into three parts that map onto the two virtues plus the luck you cannot control.
$$ \text{BS} = \underbrace{\text{Reliability}}_{\text{calibration error}} \;-\; \underbrace{\text{Resolution}}_{\text{discriminative ability}} \;+\; \underbrace{\text{Uncertainty}}_{\text{base-rate entropy}} $$
Read that as: your Brier score is your calibration error (reliability, lower is better), minus how decisively you separate winners from losers (resolution, higher is better, so it subtracts), plus the event's inherent randomness (uncertainty, which you cannot change). Two of the three terms are yours to improve. The third is the noise floor. A trader who improves resolution without wrecking reliability is building real forecast skill; a trader who just gets louder raises resolution and reliability error together and nets nothing.
The Brier Skill Score gate
None of that answers the only question that gets you to trade: are you more accurate than the market? The Brier Skill Score compares your Brier score against the market's directly.
$$ \text{BSS} = 1 - \frac{\text{BS}_{\text{model}}}{\text{BS}_{\text{market}}}, \qquad \text{BSS} > 0 \iff \text{you beat the market} $$
Read that as: the skill score is one minus the ratio of your Brier score to the market's, so it is positive only when your score is lower, meaning your forecasts are more accurate than the capital-weighted consensus. A positive score is a necessary condition for profitable informational trading, not a sufficient one, because execution and sizing can still lose money on a real edge. But a non-positive score is a full stop. If you cannot beat the market on historical resolutions, you have no informational edge, and every trade you place on your "view" is the belief-without-calibration anti-pattern from the article on the six ways to lose. Compute the score on your own logged predictions before you scale. The old article "Why Forecast Accuracy Is Not Enough in Market Making" makes the companion point that raw accuracy without the right loss function misleads; the skill score against the market is the loss function that matters here.
KEY POINTS
- A prediction-market price is not a frequentist probability. It is the capital-weighted consensus, the point where the marginal trader is indifferent, and rich wrong traders move it more than poor right ones.
- Capital flows from inaccurate to accurate participants over time, a Darwinian filter on money, not opinions. The aggregate is empirically strong, beating polls about 74% of the time across five presidential cycles.
- Coherent prices can still be wrong under five conditions: capital concentration, thin liquidity, short horizons, strategic manipulation, and extreme probabilities. Each is a broken averaging mechanism, not proof your opinion is right.
- Calibration means your 70% happens 70% of the time; sharpness means you commit near 0 and 1. You need both. Calibrated-but-flat is useless; sharp-but-miscalibrated gets you sized into ruin.
- The Brier score decomposes into reliability (yours to fix), resolution (yours to fix), and uncertainty (the noise floor).
- The Brier Skill Score against the market is the gate. Positive means you beat the market and may trade on a view; non-positive is a full stop. Compute it on your logged predictions before scaling.
References
- Interpreting the Predictions of Prediction Markets - Manski (2006)
- If You're So Smart, Why Aren't You Rich? Belief Selection in Complete and Incomplete Markets - Blume and Easley (2006)
- Prediction Market Accuracy in the Long Run - Berg et al. (2008)
- Verification of Forecasts Expressed in Terms of Probability - Brier (1950)
- Prediction Markets - Wolfers and Zitzewitz (2004)