9.21 Separate Detection from Execution: A Three-Layer, Typed-Agent Architecture
Wire your solver to your order router and one crash takes down both. Separate detection from execution behind a trade-proposal interface, stack three layers on three clocks, and let a fast scanner trigger the slow solver only where it pays.

The moment your solver is also your order router, one crash takes down both. A structural-arbitrage solver runs for thirty minutes on a hard problem, hits an edge case, and dies. If that same process was responsible for filling the proposals it computed an hour ago, those fills die with it, and you are now holding a half-legged position on a market that has moved. Wire detection and execution together and every failure in one becomes a failure in both, every scaling decision for one constrains the other, and you cannot test either without the other live. The fix is a design rule that predates prediction markets and survives them: keep the thing that finds trades separate from the thing that fills them.
The old article "The Difference Between a Trading Rule, a Strategy, and a Portfolio" makes the layered version of this argument for signals, that a rule, a strategy, and a portfolio are different objects living in different files and failing for different reasons. The same discipline scales up to a live prediction-market system running several strategies at once, structural arbitrage, informational directional bets, and market making, each with its own detection logic, sizing needs, and ways to break. Coupling them is the mistake. Separation is the architecture.
The separation principle
Split the system into two halves that talk through one narrow interface. Opportunity engines answer what to trade. Execution engines answer how to fill it. Between them passes a single object: a trade proposal.
| Opportunity engine (what to trade) | Execution engine (how to fill) |
|---|---|
| A0: structural arbitrage solvers | Order construction |
| A1: fast constraint scanners | Parallel submission, under 30 ms |
| A2: market-making quoters | Fill monitoring |
| B0: Bayesian directional agents | Partial-fill handling |
| R: regime detection and gating | Post-trade accounting |
Three reasons force the split, and each one is a failure you avoid.
Independent scaling. Detection wants high-throughput market monitoring, watching thousands of order books and dependency graphs at once. Execution wants low-latency I/O, getting one set of orders to the mempool as fast as physically possible. Those are different machines with different bottlenecks, and jamming both onto one process means neither is tuned right.
Independent failure. When the integer-programming solver crashes, the execution engine keeps filling the proposals it already holds. When execution latency spikes because the chain is congested, the opportunity engine keeps detecting and queuing. Neither outage cascades into the other. This is the same logic behind the old article "The Death of the Single-System Trader," that a single coupled point of failure is how a system dies quietly, and the answer is structural independence rather than one monolith you pray does not fall over.
Independent testing. Opportunity engines backtest on historical data with no live execution at all. Execution engines test against synthetic orders with no real edge required. Decoupled, you can validate each half in isolation, which is the only way to know which half is actually broken when live performance disappoints.
Three layers, three questions, three latency budgets
Inside that split, stack three layers, each answering one question on its own clock.
Layer 1, inference, answers what is happening right now. It ingests WebSocket price feeds, order-book snapshots, on-chain events, and news, and it outputs price vectors, a regime classification, and the dependency graph linking related markets. Budget: under 100 milliseconds for prices, under 10 seconds for a regime update.
Layer 2, decision, answers what should we do. It takes Layer 1's outputs plus current portfolio state and risk parameters, runs arbitrage detection, the Bregman projection from "Arbitrage Is Just Projection," and Kelly sizing, and it emits trade proposals of the form market, direction, size, limit price. Budget: under 1 second for a simple arbitrage check, up to 30 minutes for a full Frank-Wolfe projection on a hard combinatorial problem. That wide spread is not sloppiness. The article "Frank-Wolfe: Solving a Quintillion-Vertex Problem in 100 Steps" explains why a genuinely hard structural problem can take real wall-clock time to converge, and the architecture has to tolerate a Layer 2 component that thinks for half an hour without stalling everything else.
Layer 3, execution, answers did we get filled. It takes proposals, queries the live order book and a gas oracle, constructs orders, submits them in parallel, monitors fills, and handles partials. Budget: under 30 milliseconds from decision to mempool. That number is not arbitrary either. The article "Execution Is Part of Expected Value" shows why all legs of a multi-leg arb have to land inside one Polygon block or the price drifts between them, and the 30-millisecond target is what it takes to make that window.
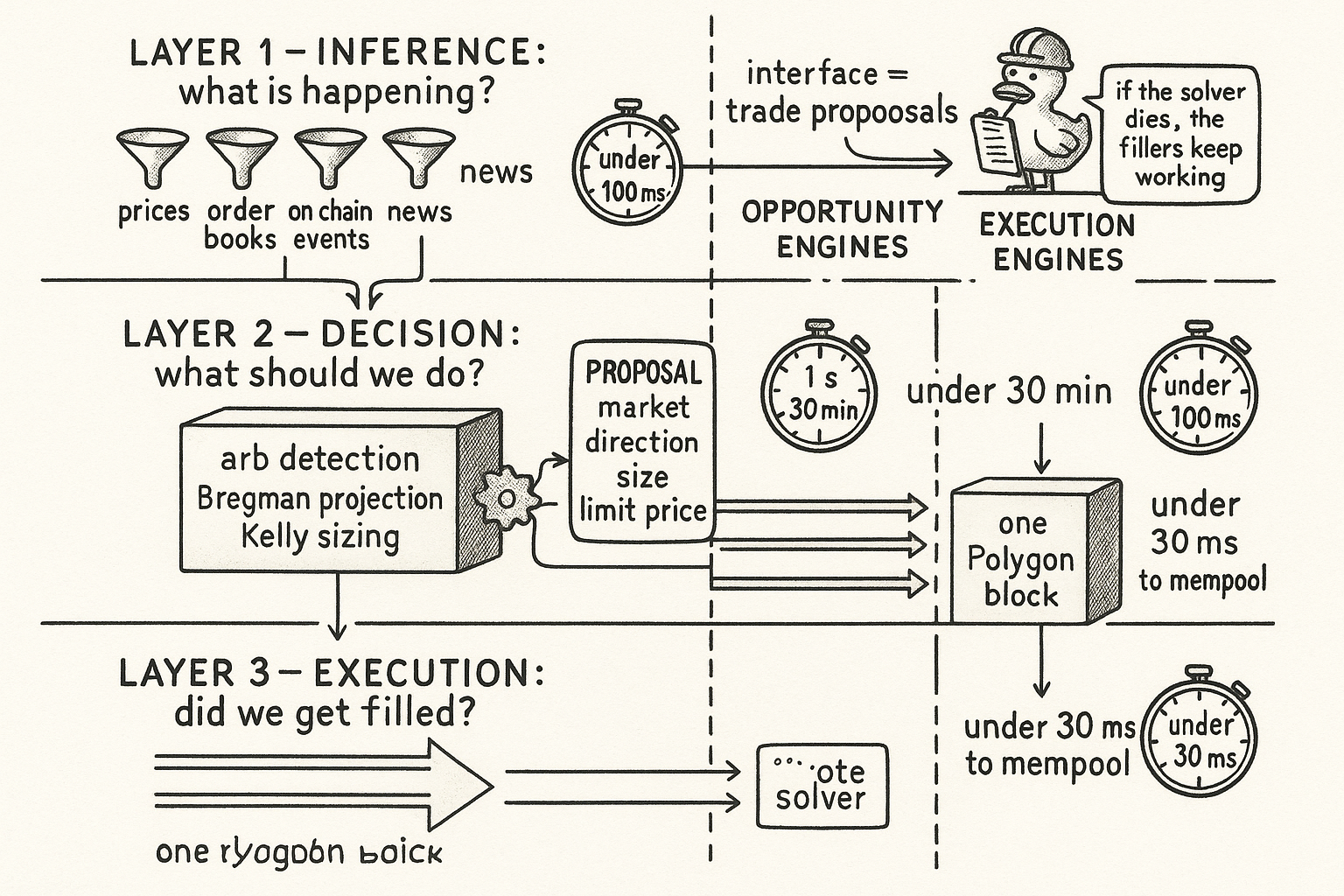
Typed agents, and the fast-scanner-triggers-deep-solver trick
Not every opportunity engine is the same shape. Type them by edge source, speed, and compute cost, and the system becomes legible: you know what each agent is for, how fast it runs, and how much it costs to run.
| Agent | Edge source | Speed | Compute |
|---|---|---|---|
| A0: structural arb solver | Structural | Seconds | High, integer-programming solver |
| A1: fast constraint scanner | Structural | Milliseconds | Low, linear checks |
| A2: market maker | Microstructure | Milliseconds | Medium |
| B0: Bayesian directional | Informational | Seconds | Medium |
| R: regime detector | Regime | Seconds | Low |
Each agent maps to a strategy the pillar already built. A0 runs the projection machinery. A2 quotes with the make-or-take logic from "Fast Fills Are Bad Fills." B0 runs the posterior from "Bayesian Edge in Log-Odds." R is the regime gate from "The Term Structure of Prediction-Market Strategy and Crowding," and it does the most valuable thing in the whole system, telling the others when to stand down.
The A0-A1 pairing is the pattern worth stealing. Running a full integer-programming solve on every price tick across thousands of markets is impossible, the compute cost is too high. So A1, the fast constraint scanner, runs cheap linear checks in milliseconds across everything, and when it spots a cheap violation that smells like an arbitrage, it triggers A0 to run the expensive full solve on that one market. A fast, dumb pre-filter guards a slow, smart solver. You get millisecond coverage of the whole market and second-scale depth only where it pays, instead of choosing one or the other.
KEY POINTS
- Coupling detection and execution means one crash kills both, one scaling decision constrains both, and you cannot test either in isolation. Separate them behind a single narrow interface, the trade proposal.
- Three reasons to separate: independent scaling (detection wants throughput, execution wants low latency), independent failure (a dead solver still lets fillers work), independent testing (backtest opportunity engines on history, test execution engines on synthetic orders).
- Three layers, each with its own clock. Inference, what is happening, under 100 ms for prices. Decision, what should we do, 1 second to 30 minutes for a full projection. Execution, did we get filled, under 30 ms to mempool so all legs land in one block.
- The 30-minute decision budget and the 30-millisecond execution budget are both load-bearing: hard combinatorial projections genuinely take time, and multi-leg arbs genuinely need one-block execution.
- Type your agents by edge source, speed, and compute: A0 structural solver, A1 fast scanner, A2 market maker, B0 Bayesian directional, R regime detector. Each maps to a strategy the pillar already built.
- The best latency trick is A1 triggering A0: a cheap millisecond scanner across all markets fires the expensive integer-programming solve only where a violation appears. Full-market coverage plus deep computation only where it pays.