5.40 QLike: The Right Loss Function for Vol Forecasting
MSE on variance is the wrong ruler for vol forecasts. QLike is optimal without knowing the distribution and punishes underestimating vol more than overestimating, matching the maker's adverse-selection cost.

Before you ask which volatility model is good, ask a smaller question that almost nobody answers honestly: how do you score a vol forecast at all? You compare predicted vol to realized vol, fine, but the comparison rule is a modeling choice with real money attached, and the default choice is wrong. Mean squared error on variance is the lazy answer, and it is poorly motivated for the thing you are measuring. The right answer, QLike, also happens to match the asymmetric way a market maker actually loses money, which is the part that makes it worth the bother.
MSE on variance is the wrong ruler
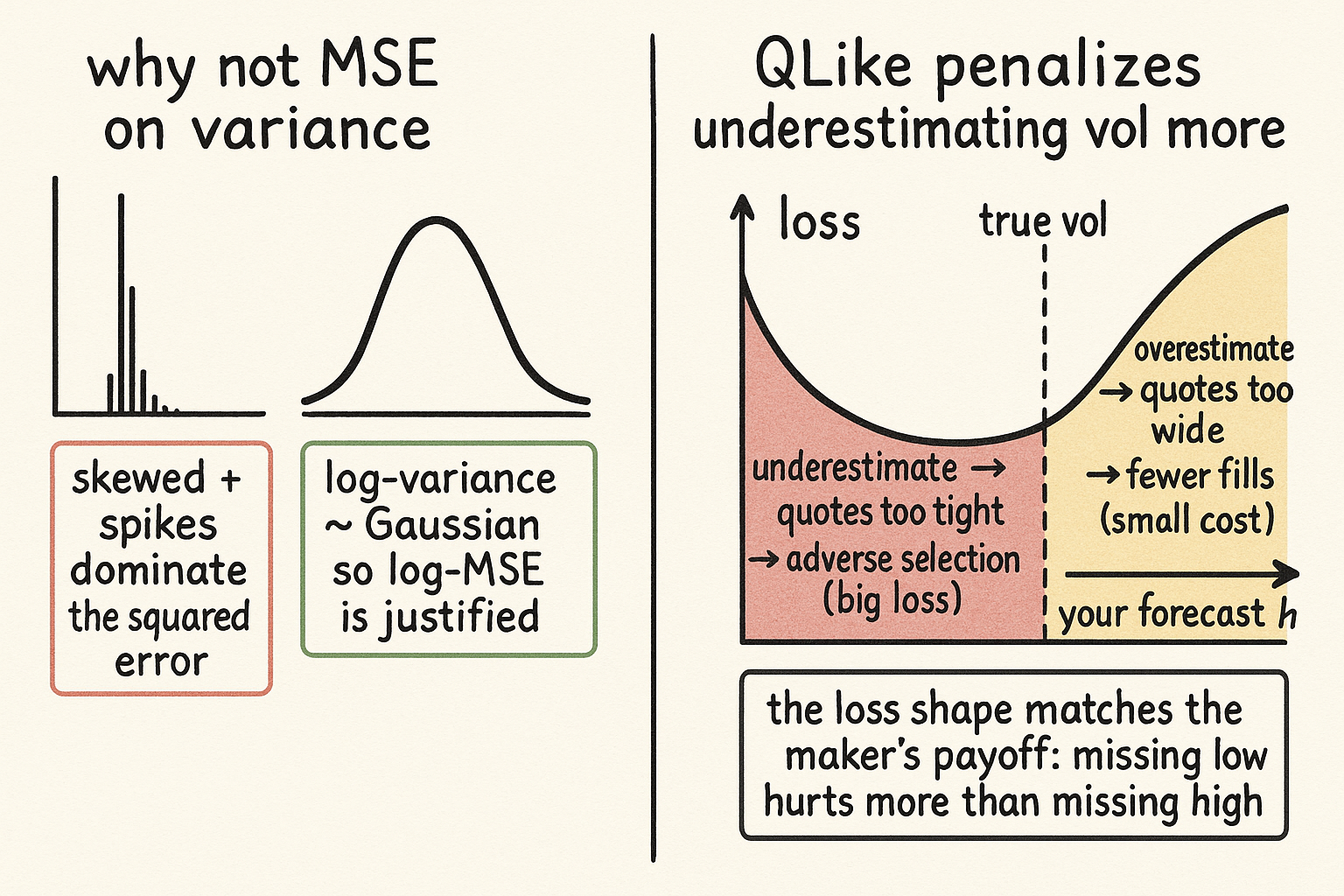
Mean squared error is not a neutral default. It is the loss you get from maximum likelihood when you assume the errors are Gaussian, so using it on a quantity quietly asserts that quantity is roughly normally distributed. Variance is not. Variance is bounded below at zero and heavily right-skewed: long stretches of small numbers punctuated by violent spikes. Run MSE on variance and the squared term lets a handful of spike days dominate the entire fit, so your model spends all its effort chasing the tail and ignores the regime you sit in most of the time.
The cheap repair is to change what you take the error of. The log of variance is roughly Gaussian, not skewed, so MSE on log-variance is the loss that maximum likelihood actually justifies here.
$$ \text{Loss} = \frac{1}{T} \sum_{t} \left( \log \sigma^2_t - \log h_t \right)^2 $$
Here h_t is your predicted variance and sigma-squared_t is the realized variance. Because you took logs, a forecast that is half the realized vol and one that is double it get penalized symmetrically, which is sane behavior on a quantity that lives on a multiplicative scale. This single change, logging before squaring, fixes most of what is wrong with the naive ruler and costs you nothing.
QLike: optimal without knowing the distribution
You can do better than log-MSE, because log-variance still carries skew and kurtosis. Any trader knows this without a plot: vol does not just spike, it spikes enormously, then sits in unusually quiet stretches, then drifts through the middle, so the distribution is a lumpy mixture, not a clean bell. The loss best motivated under that mess is QLike.
$$ \text{Loss} = \frac{1}{T} \sum_{t} \left[ \frac{\sigma^2_t}{h_t} - \log\!\left(\frac{\sigma^2_t}{h_t}\right) - 1 \right] $$
The term in brackets depends only on the ratio of realized to predicted variance. When the forecast is perfect that ratio is 1, the bracket is zero, and the loss is at its floor. The strength of QLike is that you can show it is optimal under extremely relaxed assumptions about the underlying distribution. You do not need to know what generates the vol. It can be a mixture of regimes, a latent variable flipping between calm and chaos, anything, and QLike still ranks forecasts correctly. That robustness is the whole point: you are scoring a process you cannot fully specify, so you want a ruler that does not depend on specifying it.
Why the asymmetry is exactly the maker's cost
The practical reason to care sits in the shape of QLike, not its derivation. Plot the loss against the forecast for a fixed realized vol and it is not symmetric. It punishes underestimating vol, h smaller than sigma, harder than it punishes overestimating, h larger than sigma. That asymmetry is not a quirk to tolerate. It is the exact shape of a market maker's payoff.
Underestimate vol and you quote too tight. Tight quotes in a market that is moving more than you think get picked off by informed flow, and you wear the adverse selection, the bleeding "Why Forecast Accuracy Is Not Enough in Market Making" describes when a technically accurate forecast still loses money. Overestimate vol and you quote too wide, and the cost is mild: you get fewer fills, you sit out some trades, you make less. Missing low is a loss, missing high is a missed opportunity, and those are not the same size. QLike bakes that exact preference into the loss, so the model you fit with it is tuned to fear the error that actually hurts you.
Be honest about the size of the win, though. Given a decent underlying vol model, QLike versus log-MSE is rarely a game changer in raw forecast numbers. It is one of those quiet optimizations that aligns the objective with the real cost rather than buying you a large jump in accuracy. The reason to use it is correctness and the asymmetry match, not a dramatic backtest bump, and a weak vol model fit with the perfect loss is still a weak vol model.
Where it fits with the vol models
The loss function is upstream of the model and separate from it. The seasonal autoregressive build in "SAR: Seasonal Autoregressive Volatility Forecasting" is one model you could score this way; the seasonality in "Crypto Volatility Seasonality" is structure any of these losses will reward you for capturing. QLike is the referee, not a player. Pick it first, because the referee decides which model wins your selection, and a bad referee will happily crown a model that quotes too tight and bleeds to adverse selection while posting a flattering MSE.
Visualizing the loss asymmetry
KEY POINTS
- Pick the loss function before the model. Scoring a vol forecast is a modeling choice with money attached, and the default, MSE on variance, is the wrong ruler.
- MSE assumes Gaussian errors via maximum likelihood, but variance is bounded at zero and heavily right-skewed, so a few spike days dominate the fit and the model ignores the common regime.
- Log-variance is roughly Gaussian, so MSE on log-variance is the maximum-likelihood-justified repair. It penalizes half and double the true vol symmetrically and costs nothing.
- QLike depends only on the ratio of realized to predicted variance and is optimal under extremely relaxed distributional assumptions. You do not need to know the generating process, even a regime mixture.
- QLike is asymmetric: it punishes underestimating vol harder than overestimating, which matches the maker's payoff. Quote too tight and adverse selection bleeds you; quote too wide and you just miss fills.
- Be honest about the size: with a decent model, QLike versus log-MSE is a quiet correctness win, not a large accuracy jump. The loss is the referee that picks the model, so a bad referee crowns a model that quotes too tight.
References
- The Art of Currency Trading - Brent Donnelly (Amazon)
- Volatility forecast comparison using imperfect volatility proxies
- Volatility forecasts, proxies and loss functions
- Using Proxies to Improve Forecast Evaluation
- Coherent Forecasting of Realized Volatility
- Selecting volatility forecasting models for portfolio allocation purposes
- Forecasting Financial Market Volatility: A Review
- Volatility Forecasting and Return Prediction under Market Regimes
- What Good is a Volatility Model?