7.1 Synthetic Prices: EMA of Random Numbers as a Market Model
Real prices are random numbers with memory, so an EMA of noise plus a cumulative sum makes a passable synthetic chart. Generate thousands to put error bars on a backtest, but never to prove edge.

The old article "The Problem with One Sample of Market History" made the uncomfortable point that you only ever get one realized price history, one draw from a meta-distribution you cannot resample, so every backtest conclusion rests on a sample size of one universe. The old article "Monte Carlo for Trading Systems" offered synthetic-path generation as one partial workaround, while flagging that it depends on a model that might be wrong. This article gives you the simplest synthetic-price model that captures the one property most generators miss: memory. It is almost trivial to code, and that simplicity is the feature.
Prices are random numbers with memory
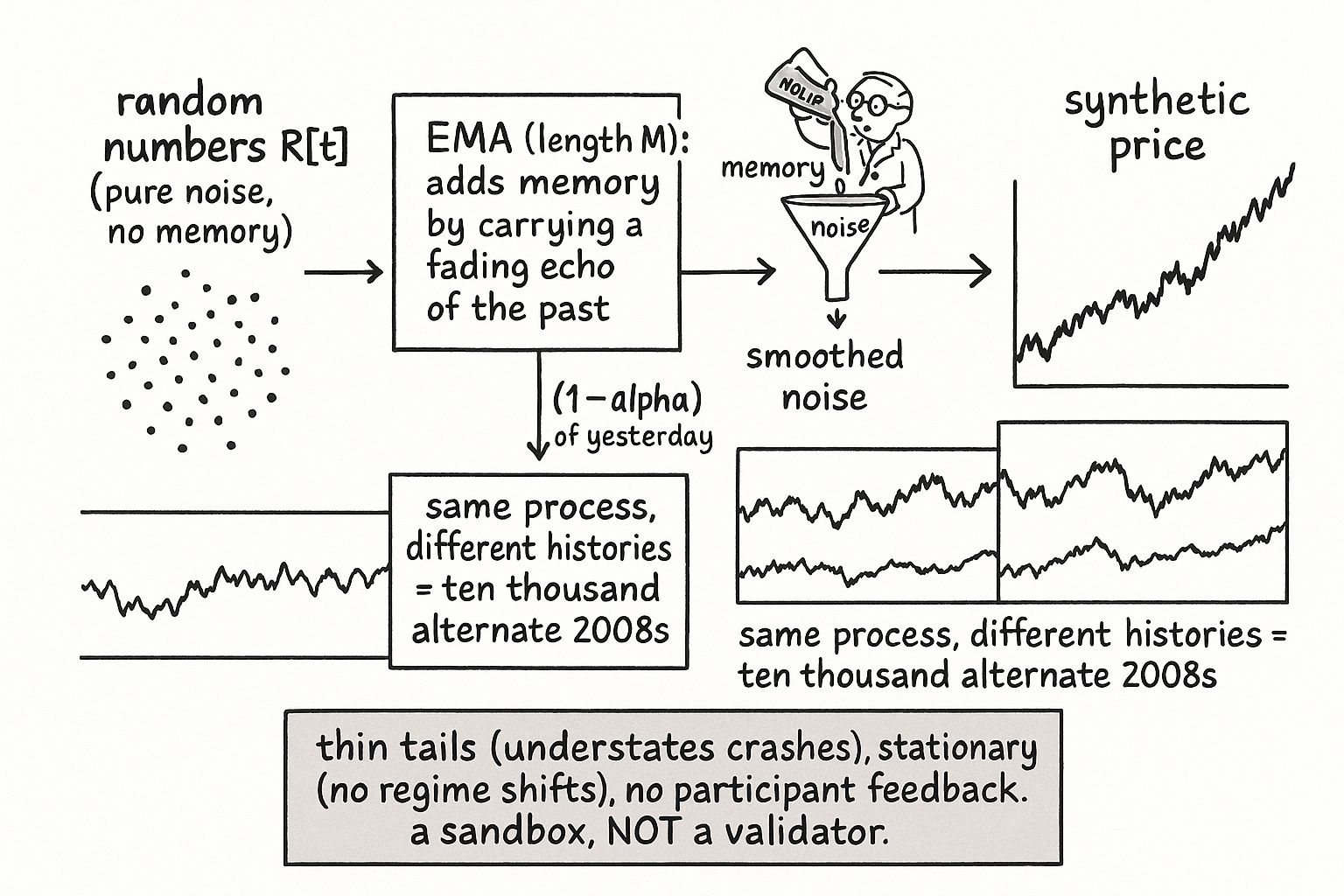
The naive synthetic price is a pure random walk: draw independent random returns, add them up. The problem is that real prices are not a fresh coin flip each bar. They carry memory, the persistence the old noise-color and Hurst articles measured, and a pure random walk has none of the right kind. Ehlers' model fixes this with one move: take an exponential moving average of random numbers. The random numbers supply the unpredictability; the EMA supplies the memory, because each output blends today's random draw with a fading echo of everything before it.
$$ P[t] \;=\; \alpha\, R[t] \;+\; (1-\alpha)\, P[t-1], \qquad R[t]\sim \text{random}, \quad \alpha=\frac{2}{M+1} $$
R[t] is a fresh random number each bar (uniform or Gaussian, it barely matters), alpha sets how much weight the new draw gets versus the carried-over history, and M is the EMA length that controls how long the memory lasts. A larger M means a smaller alpha, a longer fading echo, and a synthetic series that wanders with more persistence. That is the whole model: a low-pass filter fed noise. It is the mirror image of the roofing-filter idea, where you filtered noise out of price; here you filter noise into something that looks like price, and the result is a reasonable approximation of a real chart precisely because real prices behave like random numbers run through a memory.
The recipe in a few lines
There is nothing to it once you see the equation. Generate noise, run the EMA, and you have a price series with tunable memory.
import numpy as np
def synthetic_prices(n=2000, M=20, seed=None):
rng = np.random.default_rng(seed)
alpha = 2.0 / (M + 1)
r = rng.standard_normal(n) # the unpredictable part
p = np.zeros(n)
for t in range(1, n):
p[t] = alpha * r[t] + (1 - alpha) * p[t - 1] # the memory part
return np.cumsum(p) # integrate to a price-like level
The cumulative sum at the end turns the smoothed-noise increments into a wandering level that reads like a price chart, the integration step that, per the old noise-color article, pushes the spectral slope toward the brownian end where price lives. Change M and you change the cycle character: short M gives a jittery, fast-reverting series, long M gives long lazy swings. Change the seed and you get a different history from the same process, which is the entire point.
What synthetic prices are good for, and what they are not
The reason to bother is the one-sample problem. You cannot rerun 2008, but you can generate ten thousand histories from a process with the same memory structure and watch how your strategy behaves across all of them, turning a single fragile backtest into a distribution. That is the synthetic-path use the old Monte Carlo article described: confidence intervals on drawdown, sequence-of-returns stress tests, and kill-switch thresholds set at a percentile of the synthetic distribution rather than at the single worst day you happened to observe. It is also the cleanest way to test a cycle measurement tool, because you can build a synthetic series with a known injected cycle and check whether your periodogram recovers it.
The honest limits are exactly the ones the Monte Carlo article pressed, and they are not small. An EMA of Gaussian noise has thin tails, so it will understate crash risk badly; if you size or stress-test off this model you will be blindsided by the fat tails real markets carry. It has stationary statistics by construction, so it cannot reproduce regime shifts, volatility clustering, or the non-stationarity that breaks live strategies. And it has none of the participant feedback that makes real markets adapt to the very edges you publish. So use synthetic prices to study a tool's behavior, to build intuition, and to put error bars on metrics, never to validate that a strategy has edge. Synthetic data cannot replace out-of-sample testing, cannot correct for search-width bias, and cannot fill regime-coverage gaps. It is a sandbox with the right kind of memory and the wrong kind of tails, useful exactly as far as you remember which is which.
KEY POINTS
- You only get one realized market history (the old article "The Problem with One Sample of Market History"), so synthetic prices let you turn a single fragile backtest into a distribution, the synthetic-path workaround from the old article "Monte Carlo for Trading Systems."
- A pure random walk lacks the right memory; Ehlers' model is an EMA of random numbers, where the random draws give unpredictability and the EMA gives a fading memory of the past.
- The recipe is P[t] = alphaR[t] + (1-alpha)P[t-1] with alpha = 2/(M+1), then a cumulative sum to get a price-like level; M tunes how long the memory lasts and what cycle character the series has.
- It is the mirror of the roofing filter: there you filter noise out of price, here you filter noise into something that looks like price, which works because real prices behave like random numbers with memory.
- Use it for confidence intervals on risk metrics, sequence-of-returns stress tests, percentile-based kill switches, and testing whether a cycle tool recovers a known injected cycle.
- Its limits are severe and built in: Gaussian-EMA output has thin tails (understates crashes), is stationary (no regime shifts or volatility clustering), and has no participant feedback, so it is a sandbox for studying tools, never a substitute for out-of-sample validation.