7.3 Rust Data Server, Python Brain
Profiling a slow algo points at JSON decode, not your alpha. Put the simple hot path (decode, filter, forward) in Rust and keep the complex stateful brain (OMS, reporting, unwinding) in Python. Split at the JSON, forward binary, and match your backtest exactly.

Profile a Python trading algo that feels slow and the result almost never points where you expect. The bottleneck is not your alpha, your portfolio logic, or your sizing math. It is decoding the JSON pouring in off the websocket, with sending orders a distant second. The interesting code, the part you spent months on, barely registers on the flame graph. That single fact dictates the architecture: put the dumb, hot, repetitive work in a fast language and keep the complicated, stateful, rarely-hot work in Python. You get HFT-grade ingest without paying HFT-grade development time, because you only rewrite the part that is both slow and simple.
Where the time actually goes
A streaming algo spends its life in a tight loop: receive a message, parse it, update state, maybe act. The receive-and-parse step runs millions of times and touches every byte on the wire, so it dominates. Reaching for orjson instead of the standard library buys you a real but bounded speedup, because you are still handing bytes to Python objects, allocating dicts, and paying the interpreter for every field. It is a band-aid on the right wound. The structural fix is to never let those bytes reach Python as JSON at all.
$$ \text{loop latency} \;\approx\; \underbrace{t_{\text{decode}}}_{\text{dominant}} \;+\; t_{\text{logic}} \;+\; \underbrace{t_{\text{send}}}_{\text{runner-up}} $$
Read it as: the time around your loop is mostly the decode cost, plus a usually-small logic cost, plus the order-send cost, and the decode term is the one that scales with message volume and swamps the rest in a busy market. Optimize the dominant term and the loop gets fast. Optimize your logic, the term you enjoy working on, and you move a rounding error.
The split: Rust ingests, Python decides
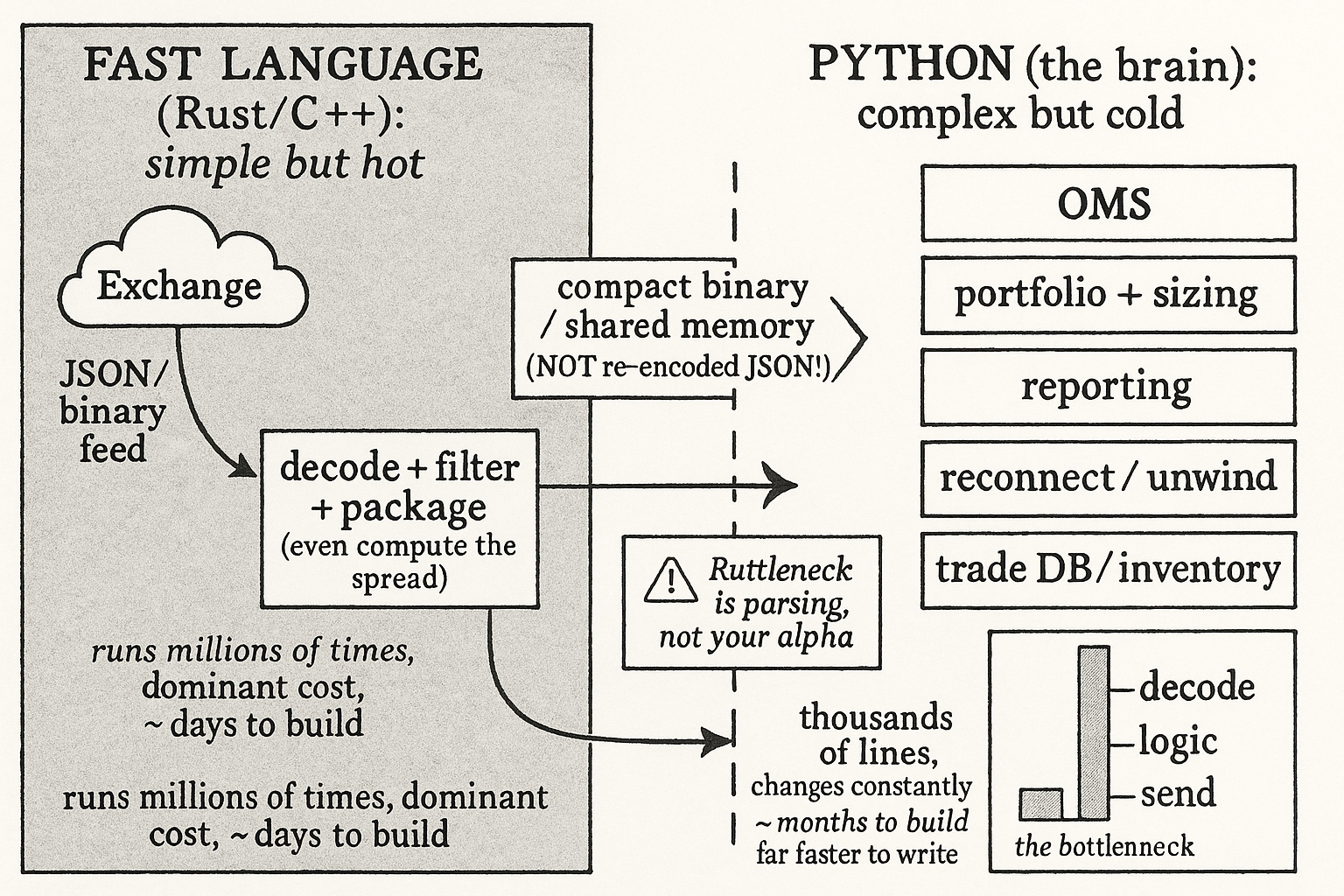
Write the data plane as its own small program in a fast language, Rust, C, C++, or Java, whatever you can stand. Its only job is to connect to the exchange, decode the binary or JSON feed, package the result into a compact internal format, and forward it to the Python process. Because it is just streaming and reshaping data, it is a simple program you can finish in days, not a system. And since you are already in that program, push more work upstream: filter out updates that do not matter, downsample, even compute the spread or the signal on the server and forward the result instead of the raw book. The less the Python side has to decode, the less the dominant term costs.
Python keeps the brain. Order management, portfolio state, position sizing, reporting, reconnection logic, unwinding, server controls, the trade database, inventory tracking, every messy edge case lives in Python where it is fast to write and fast to change. This is the part that takes months, and it takes months because of the fiddly stateful detail, not because of compute. In my experience that stateful logic runs at least twice as slow to write in Rust as in Python, and the gap widens on the gnarly edge cases, so building the brain in Rust would balloon your slowest, most error-prone work to speed up code that was never the bottleneck. You split the system exactly along the line where speed matters and complexity does not.
Why this boundary and not "rewrite it all in Rust"
The instinct after a slow profile is to rewrite the whole thing in the fast language. That trades a small, contained win for a large, ongoing cost. The hot path, ingest and forward, is a few hundred lines and changes rarely. The brain is thousands of lines and changes constantly as you add strategies, handle a new exchange quirk, or patch the way you unwind on a disconnect. Putting the volatile, complex code in the language that is slow to write means every change costs you several times more, forever, in exchange for speeding up logic that contributed almost nothing to latency. Keep the boundary at the JSON, where the fast side is simple and stable and the slow-to-write side is where all the real engineering lives.
This is the infrastructure that makes event-driven trading practical. The old article "Continuous, Event-Driven Trading vs Bar-Based Research" argued a maker must act on events as they land, not on a bar clock, and a pure-Python ingest loop chokes exactly when events cluster and the decode term spikes. The Rust front end absorbs the burst so the Python brain still sees every event in time to act. There is a backtest catch, the one the old article "Backtest Integrity Checklist as Code" keeps warning about: if your Rust server filters, downsamples, or precomputes features, it must do so identically to your research pipeline, or you have train-serve skew, a strategy validated on one transform and traded on another. The fast preprocessor is now part of your feature definition, so it has to match the backtest byte for byte.
The boundary's own costs
Two languages means two build systems, two sets of bugs, and a serialization layer between them, and that layer can quietly hand back the latency you saved. Forward the data as JSON over a socket and Python pays the decode cost anyway, so you gained nothing. Use a compact binary format, shared memory, or a zero-copy transport so the Python side reads structured fields without re-parsing text. Watch the failure modes that now span the boundary: if the Rust feed dies, the Python brain must notice and unwind rather than trade on a frozen book, so the reconnection and stale-data logic, already in Python, has to monitor the server too. And keep the feature parity discipline above front of mind, because a mismatch between the Rust preprocessor and the research code is the kind of bug that passes every test and loses money live.
Visualizing the split
KEY POINTS
- Profiling a slow streaming algo points at JSON decode first and order send second; your alpha and portfolio logic are a rounding error, so optimize the decode term, not the code you enjoy.
orjsonis a bounded band-aid because Python still allocates objects per field; the structural fix is to never let raw JSON reach Python.- Write the data plane as a small fast-language program that decodes, filters, packages, and even precomputes the spread or features, then forwards a compact format. It is simple and takes days.
- Keep the brain in Python: OMS, portfolio, sizing, reporting, reconnection, unwinding, controls, trade DB, inventory. This is the months-long work, and that stateful logic runs at least twice as slow to write in Rust.
- Split at the JSON boundary because the hot path is small and stable while the brain is large and volatile; rewriting the brain in Rust triples your hardest work to speed up code that was never slow.
- This makes event-driven trading practical (the old article "Continuous, Event-Driven Trading vs Bar-Based Research"), but any filtering or feature computation on the fast side must match your research pipeline exactly, or you get the train-serve skew the old article "Backtest Integrity Checklist as Code" warns about. Forward binary, not JSON, or you pay the decode cost twice.