5.36 Reconstructing the Order Book from Incremental Deltas
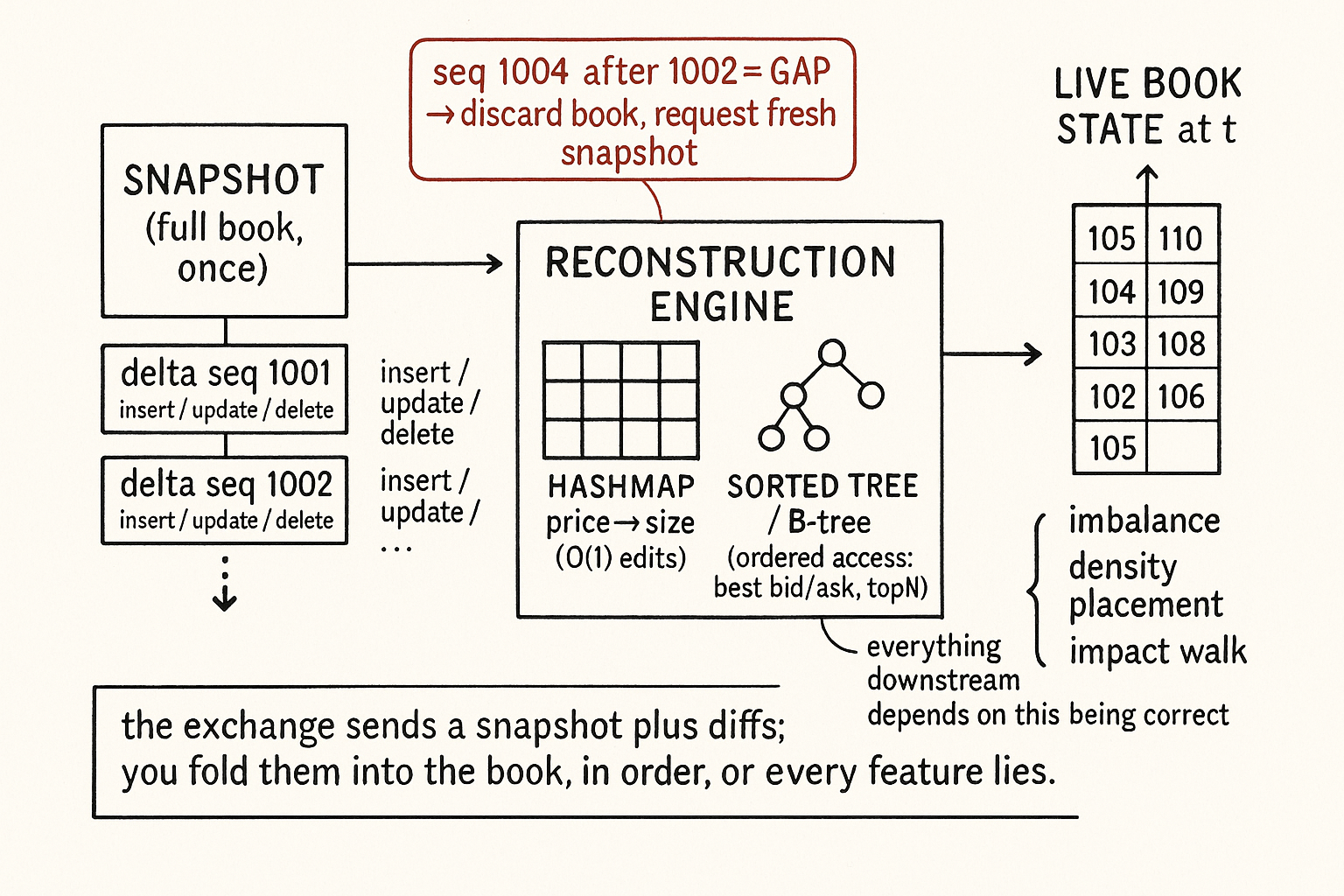
The exchange never hands you the order book, just a snapshot plus a firehose of deltas. Fold them in order using a hashmap for O(1) edits and a sorted tree for best bid/ask. Miss one sequence number and every feature silently lies.

Every microstructure feature in this pillar assumes you have the order book. Order book imbalance from the old article "Order Book Imbalance: The First Microstructure Feature to Test," the density placement, the spoofing detection, the market-impact walk, all of them read the full state of resting liquidity at each moment. None of it works until you can produce that state, and the exchange does not hand it to you. It hands you a snapshot once and then a firehose of changes, and you have to fold those changes back into a live book yourself. This is the unglamorous engine under the entire pillar, and the notebook from the old article "Order Book Imbalance Backtest" silently depends on it.
What the exchange actually sends
You get two things on an L2 feed. First, a snapshot: the full book at one instant, every price level with its resting size, sent once when you connect. Second, an endless stream of incremental deltas: tiny messages each saying "at this price, the size is now this," or "this price level is gone." The exchange does not resend the whole book on every change because that would be enormous and slow. It sends the diff, and reconstructing the book means starting from the snapshot and applying every delta in order.
A delta is one of three operations at a price level. An insert adds a level that did not exist. An update changes the size at a level that does. A delete removes a level whose size went to zero. Critically, a delta gives you the new absolute size at that price, or tells you to remove it, it is not a relative change you add, it is a replacement. Apply it by overwriting whatever you had at that price.
$$ \text{book}_t = \text{snapshot}_0 \;\oplus\; \delta_1 \oplus \delta_2 \oplus \dots \oplus \delta_t $$
Read it as: the book at time t is the initial snapshot with every delta folded in, in sequence, where each fold either sets a price level to a new size or removes it. The book is the snapshot plus the running sum of changes, and any feature you compute reads off book at t.
The data structure: a hashmap and a sorted tree
The naive implementation is a list of levels you scan and edit. It is too slow, because deltas arrive thousands per second and each one would force a linear search. You need two structures working together, one for finding a level fast and one for keeping levels sorted.
The hashmap maps price to size. When a delta lands for a price, you look it up in O(1), overwrite the size, or delete the key. That handles the update itself at constant cost no matter how deep the book. But a hashmap has no order, and every feature you want, the best bid and ask, the top-N levels for imbalance, the level-by-level walk for impact, needs the prices sorted. So you pair the hashmap with a sorted structure, a balanced binary search tree, a B-tree, or a red-black tree, keyed by price. The tree keeps the levels in price order so the best bid is the max of the bid tree and the best ask is the min of the ask tree, both reachable in logarithmic time, and an in-order traversal gives you the top levels for any depth-based feature.
The split is deliberate: the hashmap gives constant-time edits, the tree gives ordered access, and you maintain both on every delta. Insert a new price: add to the hashmap and the tree. Update a size: overwrite in the hashmap, and if the price already existed the tree needs no reorder. Delete a level: remove from both. Bid and ask sides are two separate pairs of structures, mirror images.
Sequence numbers are the whole game
Reconstruction is correct only if you apply deltas in exactly the order the exchange produced them, with none missing. Feeds carry sequence numbers for this reason: each message is stamped, and consecutive messages must have consecutive numbers. If you receive sequence 1004 right after 1002, you dropped 1003, and your book is now wrong, silently, because you applied a change to a state that had not received its predecessor. From that point your imbalance, your spreads, your everything are computed on a corrupted book.
The discipline is mechanical. Track the last sequence number you applied. If the next message is not exactly one higher, you have a gap, and the only safe response is to discard your book, request a fresh snapshot, and resynchronize. Do not paper over a gap by applying the out-of-order message; a book that is quietly wrong is worse than no book, because it produces confident garbage features that poison every model downstream. This is the single most common way a reconstruction engine fails in production, and it fails without an error message unless you check the sequence.
Where it sits and how to build it
The reconstruction engine is the prerequisite for the whole pillar, which is why this is a Pillar 7 engineering piece rather than a strategy one. It produces the book state that the imbalance feature, the density placement, and the impact walk all consume. Build it as its own component, not tangled into your strategy code, because it runs hot, thousands of deltas a second, and it benefits from being written in a fast language while your strategy logic stays in something slower and more flexible. A common architecture splits exactly here: a performant data server folds the deltas and maintains the book, then hands the clean state or the precomputed features to a Python strategy, keeping the high-frequency churn out of the slow language.
A worked sanity check before you trust it: reconstruct the book from a feed, and independently subscribe to the exchange's periodic full snapshots if it offers them. Every time a fresh snapshot arrives, compare it to your reconstructed state. They must match exactly. If they drift, you are dropping or misordering deltas, and the snapshot comparison is the only way you will catch it, because the reconstruction itself never complains.
Visualizing the reconstruction
KEY POINTS
- Exchanges send a one-time full snapshot then a firehose of incremental deltas; the live book is the snapshot with every delta folded in, in order.
- A delta gives the new absolute size at a price (insert, update, or delete), not a relative change, so you apply it by overwriting or removing that level.
- Use two paired structures: a hashmap (price to size) for constant-time edits, and a sorted tree (B-tree or red-black) for ordered access to best bid/ask and top-N levels. Maintain both on every delta, one pair per side.
- Sequence numbers are the whole game. A gap means you dropped a message and your book is silently wrong; the only safe response is to discard, request a fresh snapshot, and resync.
- A quietly-wrong book is worse than no book because it produces confident garbage features that poison every downstream model.
- Build it as a separate hot component (often a fast-language data server feeding a slower strategy), and validate by comparing your reconstruction against the exchange's periodic snapshots, they must match exactly.
References
- Limit Order Books: A Survey (Gould, Porter, Williams, McDonald, Fenn, Howison)
- Building Low-Latency Market Data Systems and Order Book Reconstruction
- Data Structures for Real-Time Limit Order Book Maintenance
- Handling Gaps and Resynchronization in Exchange Market Data Feeds
- The Art of Currency Trading - Brent Donnelly (Amazon)
- Reconstructing Full Limit Order Books for Kalshi from WebSocket Data
- Deep Order Flow Imbalance: Extracting Alpha at Multiple Horizons from the Limit Order Book
- The Short-Term Predictability of Returns in Order Book Markets: A Deep Learning Approach
- Learning from the Book: AI Evidence on Short-Run Market Efficiency
- Major Issues in High-frequency Financial Data Analysis: A Survey of Limit Order Book-based Methods
- DeepLOB: Deep Convolutional Neural Networks for Limit Order Books
- Order Book Filtration and Directional Signal Extraction at ... - arXiv
- HydraExchange