4.35 Currency Strength from Pair Decomposition: One Matrix, Every Currency
Every FX pair blends two currencies. Here is how to un-mix them with one matrix and ridge least squares, why it reconstructs every pair at 0.999, and why that still is not an edge.

Every FX pair is a quotient. EURUSD is the price of the euro measured in dollars, so a move in EURUSD tells you nothing on its own about whether the euro rose or the dollar fell. Both produce the same green candle. Traders stare at a chart of one pair and narrate it as a story about one currency, when the number in front of them mixes two. Currency strength models try to split that quotient back into its parts, one line per currency, so you can ask the question the pair refuses to answer: who actually moved?
This is the cleanest idea in the currency-strength world and the one most often dressed up as a signal it is not. The decomposition itself comes from the Dekalog Blog post "Currency Strength Revisited", which sets up the algebra and solves it bar by bar with a numerical optimizer. The version here keeps the algebra and throws out the optimizer. We will build it, check that it reconstructs the original pairs, and then say plainly what it does and does not give you.
The identity hiding in every pair
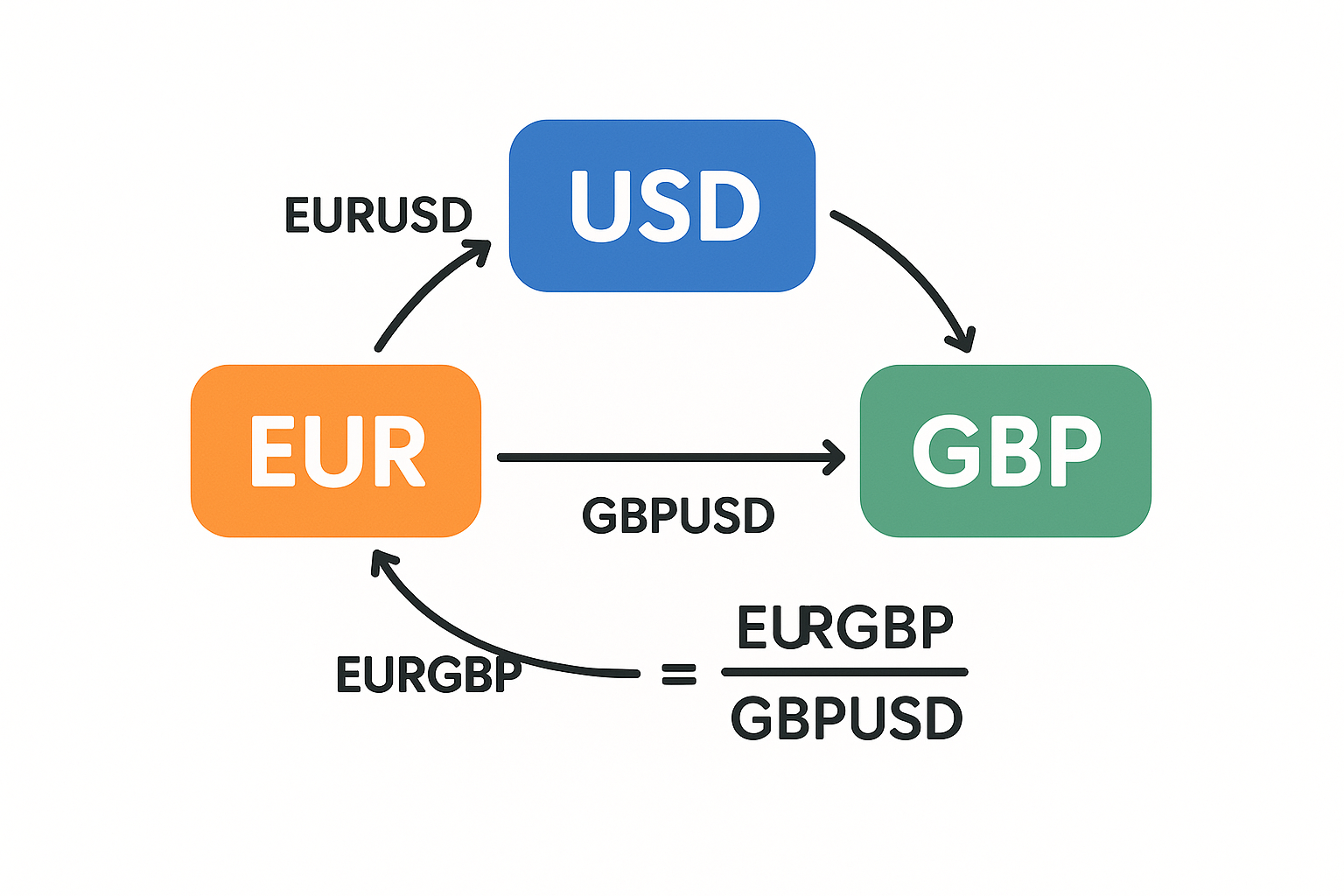
Start with three currencies and the prices that connect them. Call the dollar value of one euro EURUSD, the dollar value of one pound GBPUSD, and the pound value of one euro EURGBP. These three are not independent. If you could buy euros with dollars, sell those euros for pounds, and sell the pounds back to dollars, any mismatch would be free money, and the interbank desks closed that gap a long time ago. So the cross holds:
$$ \text{EURGBP} \;=\; \frac{\text{EURUSD}}{\text{GBPUSD}} $$
Read it slowly. The pound-price of a euro equals the dollar-price of a euro divided by the dollar-price of a pound. The dollar cancels. That cancellation is the whole game: each pair is a ratio of two underlying currency "values," and if we take logs, ratios turn into differences.
Define a hidden log-value for each currency and call it strength. Then the log return of any pair over one bar is the strength change of the base currency minus the strength change of the quote currency:
$$ r_{\text{base/quote}} \;=\; s_{\text{base}} - s_{\text{quote}} $$
For EURUSD that reads as the euro's strength change minus the dollar's. For GBPUSD, the pound's minus the dollar's. The strengths are unobserved; the pair returns are observed. We have a system of equations, one per pair, and we want to solve for the per-currency strengths underneath.
Why one currency has to be the anchor
Count the unknowns. With 8 currencies you have 8 strengths, but the pairs only ever measure differences between them. Add a constant to every currency's strength and all pair returns stay identical, because the constant cancels in every subtraction. The system is underdetermined by exactly one degree of freedom. The Dekalog Blog write-up that this method comes from fixes it by pinning one currency (the dollar) as the reference, which is the same move as setting a zero on a thermometer. Strength is relative by construction. There is no absolute "the euro is strong," only "the euro is strong against this basket right now."
That basket framing is the link to the dollar index. Dean Markwick's post "Making Sense of the DXY" shows the DXY is a fixed-weight geometric average of the dollar against six currencies, which is one hand-picked anchor basket. The decomposition here generalizes that: instead of one currency measured against a frozen 1970s weighting, solve for every currency's strength against the whole board at once, weights and all, on the data you actually have.
That single fact kills most of the mysticism. A currency-strength meter is a relative ranking with an arbitrary origin, not a measurement of intrinsic value.
The slow way and the fast way
The original Dekalog Blog implementation solves the system one bar at a time. For each bar it hands the residual to a numerical optimizer (Octave's fminunc) and lets it search for the strengths that best fit that bar's pair returns. It works, and it is slow, because you re-run an optimization thousands of times, once per row, to solve what is the same linear problem with the same structure on every bar.
The structure never changes. Which currency is the base and which is the quote is fixed by the pair names, not by the data. So write that structure once as a matrix and reuse it.
Build a design matrix A with one row per pair and one column per currency. Put +1 in the base column, -1 in the quote column, zero everywhere else. EURUSD becomes a row with +1 under EUR and -1 under USD. That matrix encodes the entire "base minus quote" relationship for the whole board. Now every bar is the same linear equation r = A s, and we solve all bars in one shot.
Because the system is rank-deficient (the anchor problem above), a raw inverse blows up. Ridge regularization handles it: add a small lam on the diagonal, which both fixes the singularity and pins the solution to the minimum-norm strengths, the symmetric choice where the strengths sum to roughly zero instead of drifting off with the free constant.
$$ \hat{s} \;=\; \left(A^{\top}A + \lambda I\right)^{-1} A^{\top}\, r $$
The term AᵀA + λI is small, square, and constant, so you invert it once. Everything else is matrix multiplication. The optimizer disappears, the result is deterministic, and there is no per-bar search to converge or fail.
The code
Two functions. The first builds the constant matrix from the pair names so you never hand-encode +1/-1. The second solves every bar at once and cumulates the per-bar strength changes into an index.
import numpy as np
import pandas as pd
def build_design_matrix(pairs: list[str]) -> tuple[np.ndarray, list[str]]:
currencies = sorted({c for p in pairs for c in (p[:3], p[3:])})
col = {c: i for i, c in enumerate(currencies)}
A = np.zeros((len(pairs), len(currencies)))
for row, p in enumerate(pairs):
A[row, col[p[:3]]] = 1.0 # base
A[row, col[p[3:]]] = -1.0 # quote
return A, currencies
def build_currency_strength(closes: pd.DataFrame, lam: float = 1.0) -> pd.DataFrame:
pairs = list(closes.columns) # ["EURUSD", "GBPUSD", ...]
A, currencies = build_design_matrix(pairs)
# observed: per-bar log returns of every pair, shape (T, n_pairs)
r = np.log(closes).diff().to_numpy()
# solve all bars at once: (AᵀA + λI)⁻¹ Aᵀ applied to every row of r
solver = np.linalg.inv(A.T @ A + lam * np.eye(len(currencies))) @ A.T
s = r @ solver.T # shape (T, n_currencies)
out = closes.copy()
for c, i in zip(currencies, range(len(currencies))):
out[f"{c}_strength"] = np.nancumsum(s[:, i]) # cumulate to an index
return out
Two things matter here and both are about honesty, not speed. The strengths on bar t use only pair returns from bar t, so there is no lookahead. And the index is a plain cumsum of those one-bar changes, which means a value at any point depends only on the past. Whatever this chart shows, it does not borrow from the future.
Does it actually reconstruct the pairs?
A decomposition you cannot invert is a decoration. The test is direct: take two solved strengths, subtract them, cumulate, and you should recover the real pair. If the euro and pound strengths are right, their difference has to trace EURGBP, the pair we never fed in as a primary leg.
df = build_currency_strength(closes, lam=1.0)
synthetic = (df["EUR_strength"] - df["GBP_strength"]) # implied EURGBP path
real = np.log(closes["EURGBP"]).diff().fillna(0).cumsum() # actual EURGBP path
print(real.corr(synthetic)) # ~0.999
A correlation near 0.999 says the linear algebra works. The hidden strengths, recombined, reproduce a pair the model never solved for directly. That is the strongest claim this method can make, and it is a claim about internal consistency, not about prediction.
What the 0.999 does not buy you
Here is where most currency-strength content stops, takes a victory lap on that correlation, and pivots to selling a meter. The reconstruction being near-perfect tells you the decomposition is arithmetic done correctly. It says nothing about whether ranking currencies by strength makes money.
I ran the obvious strategies on the strength indices and they died. Cross-sectional momentum (long the strongest currencies, short the weakest, rebalanced) printed a Sharpe around -1.4 over the sample. A time-series trend filter on a single strength line scraped a Sharpe near +0.3, inside the range you get from noise plus a few lucky trends, before costs. Mean-reversion on the strength z-score landed slightly negative. None of this survives transaction costs or out-of-sample testing, and I would not trade any of it.
The reason is structural, not a tuning failure. The strength index is a recombination of the same pair returns you already had. It adds no information; it reorganizes information. A perfect attribution of where a move came from carries no claim about where the next move goes. The cumsum is a clean accounting of the past, and the past, accounted for cleanly, is still the past.
If you want a cross-currency model that reaches for actual return drivers rather than a relabeling, Dean Markwick's "A Fundamental FX Factor Model" goes the other direction: regress currency returns on macro factor proxies (rates, equities, commodities) to explain why a currency moved, not just to restate that it did. That is the harder, more honest path when the goal is prediction. The decomposition in this article is the diagnostic you run first, before you go looking for factors.
So treat this for what it is: an attribution tool. When EURUSD drops, the decomposition tells you whether the euro sagged across the board or the dollar bid up everywhere, which changes how you read the rest of your screen and whether a "EUR trade" is really a "USD trade" wearing a different ticker. That is genuinely useful for understanding a session. It is not an edge, and the moment someone charts these lines and draws trend lines on them as if they were a leading indicator, they have wandered back into the same overfit the rest of this pillar warns about, the one examined in "Cross-Pair Signals: Can EUR Predict GBP?".
KEY POINTS
- Every FX pair is a ratio of two hidden currency values, so a single pair's move cannot tell you which currency actually moved. In logs, the pair return equals base strength minus quote strength.
- The system is underdetermined by one degree of freedom. Pin one currency as the anchor (or use ridge, which picks the minimum-norm, sum-to-zero solution). Strength is always relative, never absolute.
- Replace the per-bar optimizer with one constant design matrix: rows are pairs, columns are currencies,
+1base and-1quote. Solve every bar at once with a single ridge inverse. Deterministic, fast, no lookahead. - The index is a plain cumsum of one-bar strength changes, so every value depends only on the past.
- Validate by reconstruction: the difference of two solved strengths must retrace a real pair. Around 0.999 correlation confirms the algebra, nothing more.
- It is attribution, not prediction. Cross-sectional momentum, trend, and mean-reversion on the strength lines lost or broke even in testing. Use it to see where a move came from, never to forecast where it goes.
References
- Currency Strength Revisited - Dekalog Blog (2023)
- A Fundamental FX Factor Model - Dean Markwick
- Making Sense of the DXY - Dean Markwick
- Trading Systems and Methods - Perry Kaufman (Amazon)
- Cybernetic Trading Strategies - Murray Ruggiero (Amazon)
- The Art of Currency Trading - Brent Donnelly (Amazon)
- Foreign exchange market microstructure and the WM/Reuters 4 pm fix
- Order flow, bid–ask spread and trading density in foreign exchange markets
- Co-dependence of extreme events in high frequency FX returns
- The currency that came in from the cold: Capital controls and the information content of order flow
- Liquidity in the global currency market
- Microstructure of Foreign Exchange Markets
- Return spillovers between currency factors
- On the Use of Log Returns in Finance