6.6 Why Z-Scoring Makes Ranking Cleaner
Raw signals live on different scales, so loud names dominate any sort. Z-scoring recenters and rescales into standard-deviation units, keeping the conviction pure ranking throws away.

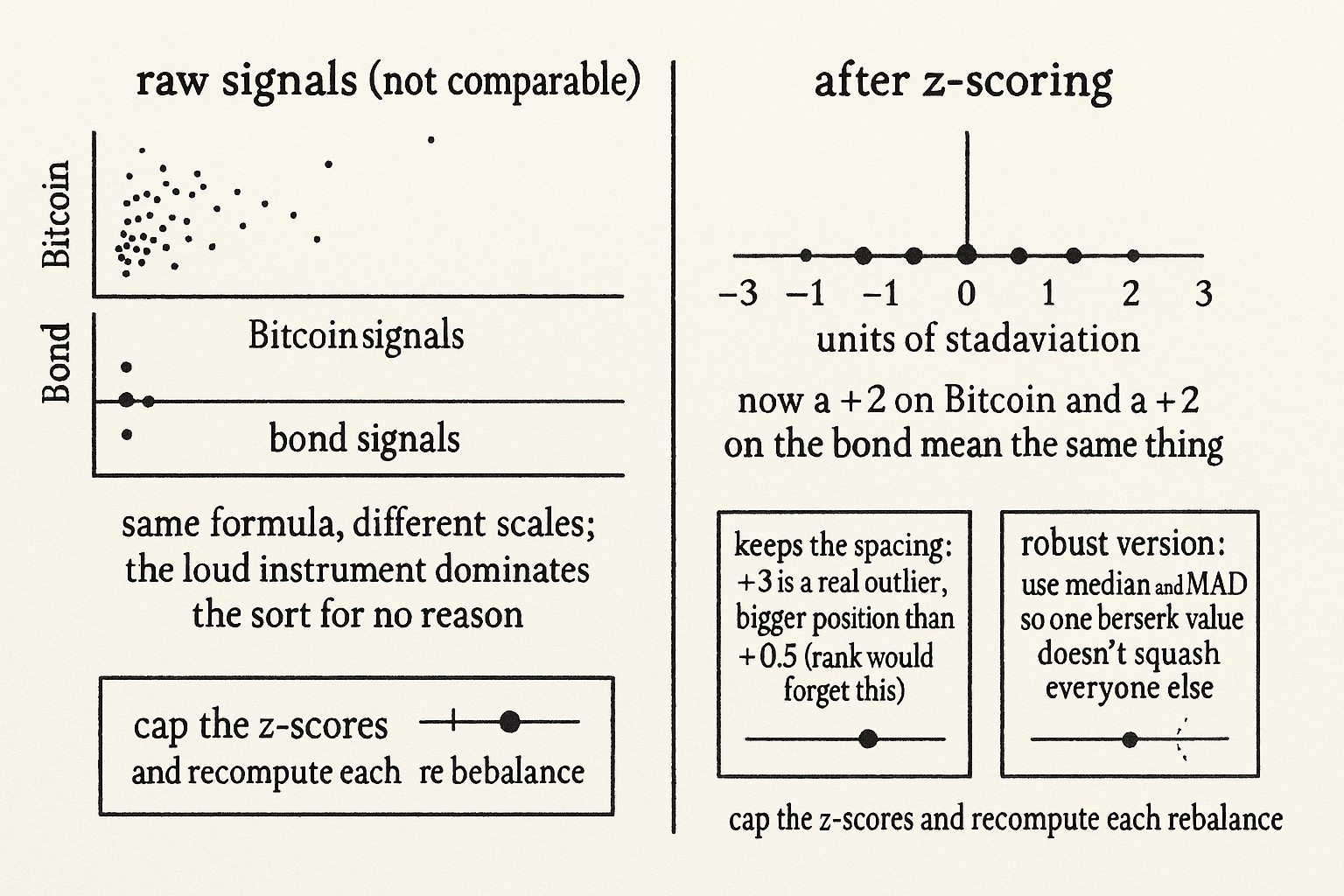
Raw signals are not comparable. A momentum reading on Bitcoin and a momentum reading on a Treasury future come out of the same formula and live on completely different scales, because one instrument moves in whole percent a day and the other in basis points. Sort a universe by a raw signal and the loud, high-volatility names dominate the top and bottom of the ranking for no reason other than their scale, drowning the quiet names that may carry the same signal strength. Z-scoring fixes the scale problem before you ever sort, and it is the cheapest piece of hygiene that separates a clean cross-sectional system from a noisy one.
This sits between "Ranked Long/Short Systems Explained" and "How to Build a Cost-Aware RSI Ranking System": the preprocessing step that makes a ranking mean what you think it means.
The transform: subtract the mean, divide by the spread
$$ z_i = \frac{x_i - \mu}{\sigma} $$
The z-score of an instrument is its raw signal value minus the mean of the signal across the universe, divided by the standard deviation of the signal across the universe. The subtraction recenters every signal on zero, so positive means above-average and negative means below-average regardless of the raw units. The division rescales so that one z-score unit means the same thing for Bitcoin and for the bond: one standard deviation of that signal's own dispersion. After z-scoring, a +2 on copper and a +2 on gold are genuinely comparable; both say "two standard deviations rich on this signal," and the units they started in are gone.
Why this is more than just ranking
A fair question: if you are going to sort anyway, why not skip z-scoring and rank the raw values directly, since ranking already discards scale? Because rank throws away too much. Ranking compresses the universe to its order and forgets the spacing, so a name that is far and away the best looks identical to a name that barely edges out the next one. Z-scoring keeps the spacing, the magnitude of how far each name sits from the crowd, which carries real information about conviction. A z-score of +3 is a genuine outlier worth a bigger position than a +0.5, and the weighting schemes from "Ranked Long/Short Systems Explained" can use that spacing directly. You z-score when you want comparability and conviction; you fall back to pure rank only when the signal's magnitudes are too unreliable to trust and you only believe the order.
The robust version, because outliers wreck the mean
Plain z-scoring has a weakness: the mean and standard deviation are themselves wrecked by outliers. One instrument with a berserk signal value drags the mean and inflates the standard deviation, which then squashes every other name's z-score toward zero, so a single crazy reading quietly mutes the whole rest of the universe. The robust fix swaps the mean for the median and the standard deviation for the median absolute deviation, both of which shrug off extreme values. You compute the median of the signal, the median of the absolute distances from that median, and z-score against those instead. The outlier still scores as extreme, which is correct, but it no longer distorts the scores of everyone else.
You also cap the z-scores at some bound, the same way a disciplined forecast framework caps a forecast at twice its average value, so that a 10-sigma data glitch cannot demand a 10x position. Recompute the mean and spread cross-sectionally each rebalance, because the right scale this month is not the right scale next month, and a z-score against a stale dispersion is just a raw signal wearing a costume.
Visualizing z-scoring
KEY POINTS
- Raw signals across instruments are not comparable because they live on different scales. Sort the raw values and high-volatility names dominate the ranking for no reason but their scale, drowning quiet names with equal signal strength.
- Z-scoring subtracts the cross-sectional mean and divides by the cross-sectional standard deviation, so every signal is recentered on zero and rescaled into standard-deviation units. A +2 then means the same thing on every instrument.
- Z-scoring beats pure rank because it keeps the spacing. Ranking forgets how far each name sits from the crowd, but a +3 is a real outlier deserving a bigger position than a +0.5, and weighting schemes can use that conviction.
- Use pure rank only when the magnitudes are too unreliable to trust and you believe only the order.
- Plain z-scoring is wrecked by outliers, since one berserk value drags the mean and inflates the standard deviation, squashing everyone else toward zero. Use the median and median absolute deviation for a robust version.
- Cap the z-scores so a data glitch cannot demand a giant position, and recompute the mean and spread each rebalance, because a z-score against stale dispersion is a raw signal in disguise.
References
- Systematic Trading - Robert Carver (Amazon)
- Trading Systems - Urban Jaekle Emilio Tomasini (Amazon)
- Trade Sizing Techniques for Drawdown and Tail Risk Control
- Optimal Portfolio Strategy to Control Maximum Drawdown
- Integrating Large Language Models and Reinforcement Learning for Financial Trading: A Sentiment-Driven Approach
- Can LLM Agents Trade Stocks Profitably In Real-world Markets?
- An Application of the Ornstein–Uhlenbeck Process to Pairs Trading
- Factor Investing and Asset Allocation
- Portfolio Structuring and the Value of Forecasting
- A Survey of Behavioral Finance
- Time series momentum
- Building Cross-Sectional Systematic Strategies By Learning to Rank
- Score-based Portfolio Choice
- Getting the Target Right in Return Prediction
- Salience theory and the cross-section of stock returns: International evidence
- Optimal Signal Extraction from Order Flow: A Matched Filter Perspective
- Do Better Volatility Forecasts Lead to Better Portfolios? Evidence from Graph Neural Networks
- Pairwise Dissimilarity and Risk-Seeking Portfolio Construction
A note on AI. The ideas, research, analysis, and conclusions in this article are my own. I use AI tools to help with editing and wordsmithing, because English is not my first language, and I am not shy about that. AI-generated ideas and AI-assisted writing are not the same thing: the first is empty slop from a generic prompt, the second is a tool for communicating years of real research more clearly. Judge the work by its substance, not by whether software helped polish the prose.